אם אני מעוניין לתת דוגמה לפער בין התיעוד הרשמי ל"מידע מהשטח" בעולם של AWS - אני נותן את הדוגמה של Terraform.
בתיעוד של אמזון, הכלי המדובר להגדרת תצורה רחבות היקף הוא Cloud-Formation (של אמזון) - אבל בפועל, אני לא מכיר אף אחד שעובד עם Cloud Formation לאורך זמן: כולם עוברים ל Terraform.
אם תשאלו מישהו שעובד כבר עם AWS - הוא כנראה יפנה אתכם ישר לשם.
Terraform הוא כלי שמנסה לספק כמה מטרות:
מה ש Terraform (מעתה אשתמש בקיצור: טרה) מאפשר - הוא להגדיר תצורה רצויה בצורה פשוטה - ו"לגרום לה לקרות".
את הגדרת התצורה עושים בקבצים עם סיומת tf. כמו זה:

"היי!" - אתם עשויים לומר, גם בעזרת aws-cli , או סתם סקריפט פייטון שמשתמש ב AWS SDK - אני יכול להרים instance בצורה פשוטה למדי! אז מה ההבדל?
יש כמה הבדלים:
נמשיך:
לאחר שיצרתי את קובץ הגדרת התצורה שלי, אני מקליד את הפקודה

מה קרה כאן?
עדיין לא קרה שומדבר. המצב שלי באמזון עדיין לא השתנה.
מה שפקודת plan עושה היא מריצה סימולציה של השינוי המתוכנן - ומספקת לי פרטים שאוכל לבחון אם זה אכן המצב הרצוי (אנחנו רוצים לצמצם טעויות בפרודקשן, נכון??).
הפלט מופיע בתצורה של diff:
ניתן גם:
כאשר אני מקליד:
עברה כחצי דקה ואני מקבל את ההודעה הבאה:

אני יכול גם להסתכל ולראות את ה instance שנוצר ב console

או פשוט לקרוא ל "aws ec2 describe-instances" ולראות אותו ב console.
לאחר ביצוע קבוצת ה apply, טרה יצר לנו שני קבצים: קובץ tfstate. וקובץ tfstate.backup.
הקבצים הללו (יש להם תוכן שונה זה מזה) מתארים את ה last-known-state של התצורה המרוחקת (כלומר: מה שקורה בפועל), והם ישמשו אותנו לפעולות הבאות.
במקרה שלנו הקבצים נוצרו רק לאחר פעולת ה apply (כי נוצר מצב שלא ניתן לשחזר בעזרת ה API של AWS בלבד), אבל גם בהרצת פקודת plan ייתכן והקבצים הללו ייווצרו / יתעדכנו.
את הקבצים הללו אני אוסיף ל gitignore. כך שלא יגיעו ל source control. מדוע - אסביר בהמשך.
נמשיך:
נעשה שינוי קטן בכדי לראות את ניהול הדלתאות של טרה:

ביצעתי שני שינויים. קראתי ל terraform plan וקיבלתי:

האמת שהייתי מצפה בשינוי instance_type שזו תהיה פעולת +/- - אבל כנראה בגלל שספציפית באמזון השוני בין t2.micro ל t2.nano הוא רק ב CPU capping - אני מניח שה instance לא מוחלף פיסית. אם הייתי משנה AMI, למשל - זו הייתה פעולת +/-.
לאחר terraform apply אקבל:

הפעולה לקחה קצת יותר זמן ממה שציפיתי - אבל הזמן הזה קשור לאמזון ולא לטרה.
כמובן שלאחר ה apply אני מעדכן את הקוד בגיט: אני מאוד רוצה snapshot נכון של התצורה שהפעלתי בכל רגע: אנחנו מדברים הרי על infrastructure as code. אולי שווה אפילו לעשות מקרו שלאחר apply מוצלח דואג להכניס לעדכן commit - שלא אשכח...
והנה המצב ב Aws Console:

ניסוי אחרון, נעשה שינוי אפילו פחות מהותי ב instance:

נריץ plan:

נריץ apply:

הפעם השינוי היה מהיר מאוד. זה רק שינוי של metadata ופה בכל מקרה לא ישתנה לי ה instance ID.
נכניס את הקוד לגיט. נבדוק את ה console עכשיו:

כדי שלא נשלם הרבה $$, בואו נסגור את ה landscape שיצרנו:
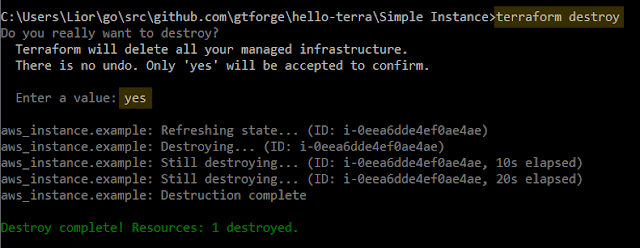
פקדנו terraform destroy, אימתנו שזה לא בטעות - yes, וזהו. תוך כמה שניות כל המכונות (כלומר: instance אחד בגודל nano) - למטה.

אם אני מעוניין בניתוח של מה המשמעות של destroy אני יכול לפקוד: terraform plan -destroy - ולקבל הדמייה / הערכה.
destroy כמובן לא ייגע במשאבים שלא הוגדרו ע"י טרה.
Great Success!
בחלק הזה אני רוצה לצלול קצת לפרטים. נסתכל שוב על הגדרת התצורה שהשתמשנו בה:

הקובץ הוא בפורמט HCL (קיצור של HashiCorp Configuration Language) ומתאר בצורה דקלרטיבית קונפיגורציה של Infrastructure. הוא מבוסס על פורמט "רזה" של JSON בשם UCL בה משתמשים בקונפיגורציה של nginx.
אפשר לכתוב את הקבצים בצורה ה JSON-ית ה"כבדה" (מרכאות מסביב לכל אלמנט, וסוגריים מסולסלים מסביב לכל Key-Value pair) - או בצורה ה"רזה". אנחנו, כמובן, ניצמד לצורה ה"הרזה".
1. בתור התחלה אנחנו מגדירים עם איזה (provider(s. קובץ טרה יכול לעבוד עם כמה ספקי-תשתיות שונים במקביל.
הפורמט הוא:
כאשר:
3. AMI, כפי שאתם בוודאי מכירים הוא Amazon Machine Image. מאיפה בוחרים AMI, אם לא שלכם? אני בוחר בעזרת ה AMI Locator של אובונטו (רק AMIs של אובונטו). שווה להכיר ש:
4. בתוך ה config של resource type מסוים יכולים להיות אובייקטים מקוננים, כמו אובייקט ה tags.
tags מסוימים, כמו Name - הם משמעותיים מאוד ב AWS.

ב HCL מגדירים:
הוא גם ייעזר ב local state על מנת לבצע:
בתיעוד של אמזון, הכלי המדובר להגדרת תצורה רחבות היקף הוא Cloud-Formation (של אמזון) - אבל בפועל, אני לא מכיר אף אחד שעובד עם Cloud Formation לאורך זמן: כולם עוברים ל Terraform.
אם תשאלו מישהו שעובד כבר עם AWS - הוא כנראה יפנה אתכם ישר לשם.
Terraform הוא כלי שמנסה לספק כמה מטרות:
- לספק תמונה אחת לכל תשתית המערכת שלנו.
- לתמוך בתצורות production מודרניות (ענן, וכו')
- לספק אופן צפוי ובטוח לעדכן את תצורת התשתית שלנו.
- לספק Workflow אחיד לעבודה מול ספקי-תשתיות שונים.
- משום מה, אנשים נוטים להניח ש Terraform מאפשר להגדיר תצורה לספק ענן אחד (נניח גוגל) ואז להפעיל אותה על ענן אחר (נניח Azure). זה בהחלט לא המצב! זה לכל היותר מיתוס!
נפתח בדוגמה
מה ש Terraform (מעתה אשתמש בקיצור: טרה) מאפשר - הוא להגדיר תצורה רצויה בצורה פשוטה - ו"לגרום לה לקרות".
את הגדרת התצורה עושים בקבצים עם סיומת tf. כמו זה:
"היי!" - אתם עשויים לומר, גם בעזרת aws-cli , או סתם סקריפט פייטון שמשתמש ב AWS SDK - אני יכול להרים instance בצורה פשוטה למדי! אז מה ההבדל?
יש כמה הבדלים:
- בעזרת טרה, אני משתמש באותה שפה ואותו תהליך אני יכול להגדיר תצורה על תשתיות שונות: AWS, גוגל, Dyn, Cloudflare - ועוד. זה קצת יותר פשוט מלהתחיל לעבוד עם כלים שונים ו SDKs שונים.
- טרה מוסיף "חוכמה" של חישוב המסלול הנכון להגיע למצב הרצוי: טרה בודק מה המצב הקיים, ומחשב אלו שינויים יש לבצע בכדי להגיע לתצורה הרצויה. לעשות את זה לבד - זו הרבה מאוד עבודה!
נמשיך:
לאחר שיצרתי את קובץ הגדרת התצורה שלי, אני מקליד את הפקודה
$ terraform plan
ומקבל את הפלט הבא:

מה קרה כאן?
עדיין לא קרה שומדבר. המצב שלי באמזון עדיין לא השתנה.
מה שפקודת plan עושה היא מריצה סימולציה של השינוי המתוכנן - ומספקת לי פרטים שאוכל לבחון אם זה אכן המצב הרצוי (אנחנו רוצים לצמצם טעויות בפרודקשן, נכון??).
הפלט מופיע בתצורה של diff:
- + - על משאב חדש שנוצר.
- - - על משאב שמבוטל.
- ~ - על משאב שעובר שינויי תצורה.
- -/+ - על משאב שמבוטל, ומוחלף במשאב אחר.
ניתן גם:
- להעשיר את הפלט בצורה מותאמת אישית, בעזרת פקודות output (או פונקציות כמו count) בהגדרת התצורה. למשל: אני רוצה לדעת איזה IP ה ELB שלי הולך לקבל, או כמה instances מסוג מסוים יהיו על מכונות spot.
- להשתמש בפקודה terraform graph על מנת לקבל גרף המתאר את סדר הפעולות המתוכנן. טרה עובד עם פורמט גרפים סטנדרטי, ואת הפלט של הפקודה ניתן לטעון ל webgraphviz.com - על מנת לצפות בגרף בצורה ויזואלית.
- הפלט של פקודת plan מסודר ע"פ סדר הא"ב על מנת לספק יכולת סריקה מהירה של התוכן.
- לשמור את תוצאת התכנון, בעזרת הפרמטר out=path-, כך שיובטח שבעת הפעולה תרוץ התוכנית שבחנתי.
כאשר אני מקליד:
$ terraform apply
עברה כחצי דקה ואני מקבל את ההודעה הבאה:
אני יכול גם להסתכל ולראות את ה instance שנוצר ב console

או פשוט לקרוא ל "aws ec2 describe-instances" ולראות אותו ב console.
לאחר ביצוע קבוצת ה apply, טרה יצר לנו שני קבצים: קובץ tfstate. וקובץ tfstate.backup.
הקבצים הללו (יש להם תוכן שונה זה מזה) מתארים את ה last-known-state של התצורה המרוחקת (כלומר: מה שקורה בפועל), והם ישמשו אותנו לפעולות הבאות.
במקרה שלנו הקבצים נוצרו רק לאחר פעולת ה apply (כי נוצר מצב שלא ניתן לשחזר בעזרת ה API של AWS בלבד), אבל גם בהרצת פקודת plan ייתכן והקבצים הללו ייווצרו / יתעדכנו.
את הקבצים הללו אני אוסיף ל gitignore. כך שלא יגיעו ל source control. מדוע - אסביר בהמשך.
נמשיך:
נעשה שינוי קטן בכדי לראות את ניהול הדלתאות של טרה:

ביצעתי שני שינויים. קראתי ל terraform plan וקיבלתי:
האמת שהייתי מצפה בשינוי instance_type שזו תהיה פעולת +/- - אבל כנראה בגלל שספציפית באמזון השוני בין t2.micro ל t2.nano הוא רק ב CPU capping - אני מניח שה instance לא מוחלף פיסית. אם הייתי משנה AMI, למשל - זו הייתה פעולת +/-.
לאחר terraform apply אקבל:

הפעולה לקחה קצת יותר זמן ממה שציפיתי - אבל הזמן הזה קשור לאמזון ולא לטרה.
כמובן שלאחר ה apply אני מעדכן את הקוד בגיט: אני מאוד רוצה snapshot נכון של התצורה שהפעלתי בכל רגע: אנחנו מדברים הרי על infrastructure as code. אולי שווה אפילו לעשות מקרו שלאחר apply מוצלח דואג להכניס לעדכן commit - שלא אשכח...
והנה המצב ב Aws Console:

ניסוי אחרון, נעשה שינוי אפילו פחות מהותי ב instance:
נריץ plan:

נריץ apply:
הפעם השינוי היה מהיר מאוד. זה רק שינוי של metadata ופה בכל מקרה לא ישתנה לי ה instance ID.
נכניס את הקוד לגיט. נבדוק את ה console עכשיו:

כדי שלא נשלם הרבה $$, בואו נסגור את ה landscape שיצרנו:


אם אני מעוניין בניתוח של מה המשמעות של destroy אני יכול לפקוד: terraform plan -destroy - ולקבל הדמייה / הערכה.
destroy כמובן לא ייגע במשאבים שלא הוגדרו ע"י טרה.
Great Success!
מה קרה כאן, בעצם?
בחלק הזה אני רוצה לצלול קצת לפרטים. נסתכל שוב על הגדרת התצורה שהשתמשנו בה:
הקובץ הוא בפורמט HCL (קיצור של HashiCorp Configuration Language) ומתאר בצורה דקלרטיבית קונפיגורציה של Infrastructure. הוא מבוסס על פורמט "רזה" של JSON בשם UCL בה משתמשים בקונפיגורציה של nginx.
אפשר לכתוב את הקבצים בצורה ה JSON-ית ה"כבדה" (מרכאות מסביב לכל אלמנט, וסוגריים מסולסלים מסביב לכל Key-Value pair) - או בצורה ה"רזה". אנחנו, כמובן, ניצמד לצורה ה"הרזה".
1. בתור התחלה אנחנו מגדירים עם איזה (provider(s. קובץ טרה יכול לעבוד עם כמה ספקי-תשתיות שונים במקביל.
- טרה תומך בעשרות "ספקי תשתיות", כולל Cloudflare, New Relic, MailGun, ועוד.
- בתוך provider מסוג aws' עלי לספק את ה region. בחרתי region זול (בכל זאת, לבלוג אין הרבה תקציבים...)
- צורת העבודה, והשפה (HCL) הם אחידים עבור כל ספק תשתיות - אבל הערכים שזמינים לכל ספק הם שונים לחלוטין. ל Dyn אין בכלל regions, אבל נדרשים לתאר את שם הלקוח (שלכם). בענן של גוגל יש לתאר region אבל גם project.
הפורמט הוא:
resource "<provider>_<type>" "<resource_name>" {
<config>
}
כאשר:
- provider צריך לתאום ל provider שהגדרנו בתחילת הקובץ
- ה type הוא ערך מתוך מרחב ערכים שמוגדל לכל provider. למשל ל dyn יש resource בשם "dyn_record"
- ה resource_name הוא שם שיזהה בצורה ייחודית את המשאב הזה בתוך ההגדרות של טרה.
- ה config הוא רשימה של שדות, שמרחב הערכים מוגדר ע"פ הצמד provider ו type.
3. AMI, כפי שאתם בוודאי מכירים הוא Amazon Machine Image. מאיפה בוחרים AMI, אם לא שלכם? אני בוחר בעזרת ה AMI Locator של אובונטו (רק AMIs של אובונטו). שווה להכיר ש:
- ל regions שונים יש AMI ID שונים: ה AMI של אובונטו בצפון וריגיניה וזה של אורגון אולי יהיה זהים ברמת הביטים - אבל יהיה להם ID אחר.
- במכונה מסוג t2.micro או t2.nano אני יכול להשתמש רק ב AMI שעובד עם hvm (וירטואליזציה) ו ebs (אחסון). סתם שווה להכיר.
- אפשר לקבל במהירות עוד מידע על AMI בעזרת הפקודה הבאה:
aws ec2 describe-images --image-ids ami-a60c23b0
4. בתוך ה config של resource type מסוים יכולים להיות אובייקטים מקוננים, כמו אובייקט ה tags.
tags מסוימים, כמו Name - הם משמעותיים מאוד ב AWS.
ב HCL מגדירים:
- ארגומנט (כמו אלו של ה resource) כקלט לקונפיגורציה. משהו שאנחנו יודעים ומציבים בקונפיגורציה.
- Attribute ("תכונה") כפלט של הקונפיגורציה בעת ההרצה - פקודת apply. משהו שלא ידענו לספק בעצמנו אבל מתאר את התצורה. למשל: כאשר אני יוצר instance ב AWS אני לא יודע איזה כתובת IP הוא יקבל - אבל ייתכן והכתובת הזו צריכה לשמש אותי לקונפיגורציה בהמשך, למשל: בכדי ליצור רשומת DNS.
- ה attributes הם חלק חשוב מה state - שנגדיר אותו מייד.
כאשר אנו מתכננים plan, טרה מאחורי הקלעים יוצר גרף (מסוג DAG) של תוכנית הפעולה להגעה למצב הרצוי. הקונפיגורציה עצמה לא מתארת את סדר הפעולות (אלא אם נוסיף אילוץ - depends_on) - טרה מחשב אותו בעצמו.
טרה ידע מתי הוא יכול למקבל פעולות - והוא ינסה לעשות זאת ככל האפשר, אבל יימנע ממקבול מתי שהוא מסוכן. למשל: כאשר אני מחליף instance ממכונה קטנה לגדולה - טרה לא יודע מה המשמעות של כמה השניות שהמכונות הללו יחיו במקביל. בגלל שזה עלול להיות מזיק - הוא יימנע מכך ויעשה את סדר הפעולות סדרתי.
קונספט חשוב נוסף הוא ה State
בטרה מדברים על:
- Last known state - המורכב מהארגומנטים השונים, משתני הסביבה בעת ההרצה, וכו' - כל מה שטרה עשוי להשתמש בו בעתיד. הוא נשמר בקבצי terraform.tfstate ו terraform.tfstate.backup.
- Actual state - המצב בפועל של התשתית שלנו. זהו מצב לא ידוע כי ייתכן ויש שינויים שלא נעשו ע"י טרה, או אפילו לא ע"י העותק הנוכחי של טרה.
לפני שטרה מבצע תוכנית או apply הוא פונה ל APIs ולומד מה שהוא יכול על ה actual state. אנחנו בהחלט רוצים להימנע מטעויות.
הוא גם ייעזר ב local state על מנת לבצע:
- מיפוי נכון, למשל ה resource x הוא בעצם instance עם id כזה וכזה ב EC2
- לשפר את מהירות הפעולה: אם instance id קיים - אני יכול להניח שכמה attributes שלו לא השתנו.
- מישהו, מתישהו, הולך להפעיל את טרה עם קבצי state שאינם up-to-date (למשל: שכח לעשות git pull לפני). אתם יודעים, כל טעות בפרודקשיין עשויה להיות אסון. לא טוב!
- כל קבצי ה state נשמרים כ plain text וכוללים את כל משתני הסביבה. יש סיכוי טוב שסודות (ססמאות, keys, וכו') יכנסו לתוכן הקבצים. אתם לא מכניסים ססמאות לתוך ה source control שלכם - אני מקווה!
בקיצור: ההמלצה הגורפת היא להכניס את הקבצים הללו ל gitignore. ולא לעדכן אותם לתוך ה source control.
אז מה עושים בקבוצה?
לטרה יש מנגנון שנקרא remote state (אולי היה אפשר לקרוא לו shared state) ששומר את ה state באחסון מרוכז (consul, S3, ועוד) - ומשתמש בהם משם. כמובן שאת שטח האכסון (למשל: S3) - חשוב להגדיר כמוצפן.
Remote State דורש קצת עבודת הגדרות - אבל הוא בהחלט הדרך הנכונה לעבוד!
לטרה יש מנגנון שנקרא remote state (אולי היה אפשר לקרוא לו shared state) ששומר את ה state באחסון מרוכז (consul, S3, ועוד) - ומשתמש בהם משם. כמובן שאת שטח האכסון (למשל: S3) - חשוב להגדיר כמוצפן.
Remote State דורש קצת עבודת הגדרות - אבל הוא בהחלט הדרך הנכונה לעבוד!
 |
| דוגמה ל folder structure של פרויקט טרה. מקור |
נקודת מפתח שאולי לא הזכרתי מספיק בטרה, היא באמת הפילוסופיה של Infrastructure as Code. אפילו שזה קוד דקלרטיבי - ישמש אתכם מאוד לעבוד בפרקטיקות טובות של קוד.
למשל: קבצים גדולים? חס וחלילה - קשה להתמצא ולקרוא את הקוד.
טרה מעודדת לפרק את הקוד לקבצים קטנים יותר: כל הקבצים בסיומת tf. ו/או tf.json. בתוך אותה התיקיה - יעברו merge לפני שיורצו.
יש כאלו שמפרקים את הפרויקט לקבצים כמו: variables, output ו main - חלוקה בהחלט לא scalable מבחינת ניהול קוד.
תצורה עדיפה היא חלוקה ע"פ תוכן: dns, instances, launch_configurations, security_groups, וכו'.
כמו כל פרויקט, וקצת מעבר - ההמלצה היא לפרק את הפרויקט לתתי פרויקטים (כמו בתרשים למעלה).
החלוקה לתתי פרויקטים היא ה bulkhead שלכם! אם משהו משתבש - אתם תרצו שהוא ישתבש ב scope מצומצם ומוגדר היטב.
כלים נוספים בשפת ה HCL הם:
מודולים
אם יש לכם 100 שירותים בפרודקשיין, אני מקווה בשבילכם שאתם לא מנהלים 100 עותקים מאוד דומים של קוד!
אתם רוצים להגדיר מודול של service_instance, של service_elb, של service_db וכו' - ולשכפל מעט עד כמה שאפשר קוד.
Interpolation (התייחסות למשאבים אחרים)
בעזרת תחביר ה interpolation אנחנו יכולים לקצר ולייעל את הקוד שלנו (וגם להשיג דברים - שאחרת פשוט לא יכולנו). התחביר נקרא לעתים גם "dirty money" והוא נראה כך:
משתנים
שניתן להגדיר פעם אחת מרכזית - ולהשתמש בהם ברחבי הפרויקט. אני מניח שאתם מכירים משתנים.
כמובן שיש עוד פרטים רבים להשלים - על מנת לעבוד איתו בצורה שוטפת.
לאורך הפוסט ניסיתי להדגיש גם את האלמנטים של Infrastructure as Code.
שיהיה בהצלחה!
----
לינקים רלוונטיים
מדריך לכתיבת מודולים בטרה: https://linuxacademy.com/howtoguides/posts/show/topic/12369-how-to-introduction-to-terraform-modules
Terraform Comprehensive Training - מצגת שנראה שמקיפה הרבה נקודות:
https://www.slideshare.net/brikis98/comprehensive-terraform-training
למשל: קבצים גדולים? חס וחלילה - קשה להתמצא ולקרוא את הקוד.
טרה מעודדת לפרק את הקוד לקבצים קטנים יותר: כל הקבצים בסיומת tf. ו/או tf.json. בתוך אותה התיקיה - יעברו merge לפני שיורצו.
יש כאלו שמפרקים את הפרויקט לקבצים כמו: variables, output ו main - חלוקה בהחלט לא scalable מבחינת ניהול קוד.
תצורה עדיפה היא חלוקה ע"פ תוכן: dns, instances, launch_configurations, security_groups, וכו'.
כמו כל פרויקט, וקצת מעבר - ההמלצה היא לפרק את הפרויקט לתתי פרויקטים (כמו בתרשים למעלה).
החלוקה לתתי פרויקטים היא ה bulkhead שלכם! אם משהו משתבש - אתם תרצו שהוא ישתבש ב scope מצומצם ומוגדר היטב.
כלים נוספים בשפת ה HCL הם:
מודולים
אם יש לכם 100 שירותים בפרודקשיין, אני מקווה בשבילכם שאתם לא מנהלים 100 עותקים מאוד דומים של קוד!
אתם רוצים להגדיר מודול של service_instance, של service_elb, של service_db וכו' - ולשכפל מעט עד כמה שאפשר קוד.
Interpolation (התייחסות למשאבים אחרים)
בעזרת תחביר ה interpolation אנחנו יכולים לקצר ולייעל את הקוד שלנו (וגם להשיג דברים - שאחרת פשוט לא יכולנו). התחביר נקרא לעתים גם "dirty money" והוא נראה כך:
 |
| אני מגדיר בתוך רשומת ה DNS את כתובת ה IP של ה ec2 instance בשם example. ערך שאי אפשר לדעת לפני הריצה. ה interpolation הוא, כמובן, כלי עיקרי לטרה לקבוע את סדר הפעולות ההרצה. |
משתנים
שניתן להגדיר פעם אחת מרכזית - ולהשתמש בהם ברחבי הפרויקט. אני מניח שאתם מכירים משתנים.
סיכום
מהסקירה הזו של טרה, אתם אמורים להבין בצורה דיי טובה מהו Terraform, מה ה workflow שלו, וכיצד הוא עובד.כמובן שיש עוד פרטים רבים להשלים - על מנת לעבוד איתו בצורה שוטפת.
לאורך הפוסט ניסיתי להדגיש גם את האלמנטים של Infrastructure as Code.
שיהיה בהצלחה!
----
לינקים רלוונטיים
מדריך לכתיבת מודולים בטרה: https://linuxacademy.com/howtoguides/posts/show/topic/12369-how-to-introduction-to-terraform-modules
Terraform Comprehensive Training - מצגת שנראה שמקיפה הרבה נקודות:
https://www.slideshare.net/brikis98/comprehensive-terraform-training
מעניין מאד, תודה רבה!
השבמחק