בחלק א' סקרנו את HTTPS מגבוה, מבלי להיכנס כל-כך לפרטים.
בפוסט זה ארצה להמשיך ולהיכנס קצת יותר לעומק.
תהליך ה Handshake

תקשורת HTTP מתבצעת על גבי TCP connection.
TCP Connection הוא של הסכמה הדדית בין 2 הצדדים כיצד לעבוד, כך שלא יהיה צריך להסכים עם כל הודעה מחדש. הסכמה על TCP connection נעשית בתהליך תלת-שלבי שנקרא "לחיצת ידיים משולשת" (three-way handshake). אני מניח שכל זה מוכר.
פרוטוקול TLS משתלב על גבי לחיצת הידיים של TCP ומוסיף את הבטי האימות וההצפנה. לצורף כך, TLS דורש עוד כארבע לחיצות ידיים בדרך. יש כמה אופטימיזציות שונות ללחיצת היד של TLS (אינני מכיר את הפרטים של רובן), והן יתרחשו אם התסריט מאפשר זאת ושני הצדדים מודעים לקיצור הדרך. בתרשים למעלה הצגתי פישוט דיי בסיסי בו ה Ack האחרון של "לחיצת-הידיים המשולשת" משמש גם להעברה של ההודעה הראשונה של ה TLS handshake, הרי הוא ה Client Hello.
הנה תקציר תהליך ה TLS handshake:
הודעה 1: Client Hello
ה Client מצהיר שהוא מוכן להתחיל בתהליך ה TLS handshake ושולח כמה פרטים: גרסאות ה TLS בהן הוא תומך, רשימה של הצפנות (סימטריות) בהן הוא תומך ועוד כמה פרטים טכניים.
כל התקשורת בשלב זה נעשית ב clear text, כלומר: ללא הצפנה.
כל התקשורת בשלב זה נעשית ב clear text, כלומר: ללא הצפנה.
הודעה 2: Server Hello + Certificate
השרת בוחר בגרסת TLS וההצפנה בהן הוא מעוניין לעבוד (בעצם: המקסימום שהוא תומך) ומצרף את המפתח הציבורי שלו עם Certificate - מספר שדות ("קובץ קצר") שמאמתים את זהותו שלו. מעין "צילום של תעודת הזהות שלו". הקובץ חתום ע"י חתימה דיגיטלית של גורם צד-שלישי מוכר. פרטים נוספים על Certificates - בהמשך הפוסט.
בשלב זה יכול השרת להחליט שהוא רוצה לאמת בעזרת HTTPS Authentication, את זהות המשתמש - ולבקש מה Client חזרה את ה Certificate שלו.
הודעה 3: העברת מפתח סימטרי
ה Client מאמת את ה Certificate של השרת (איך הוא עושה זאת - בהמשך) ומייצר מפתח סימטרי אקראי לצורך ה session הנוכחי עם השרת. אני מניח שמשימת יצירת המפתח הסימטרי ניתנה ל Client בכדי לשפר את ה scalability של השרת ("1000 מעבדים ממוצעים חזקים ממעבד-מפלצת של שרת אחד").
את המפתח הסימטרי, ה Client מצפין בעזרת המפתח הציבורי של השרת. רק בעל המפתח הפרטי המתאים - יוכל לפתוח את ההצפנה (בזמן סביר).
הודעה 4: שימוש במפתח הסימטרי לצורך אימות וסיום תהליך ה TLS handshake
בשלב זה השרת משתמש במפתח הפרטי שלו כדי לפענח את ההודעה הקודמת, לחלץ את המפתח הסימטרי - ולעבור להשתמש בו.
ההודעה הראשונה שנשלחת ל Client היא הודעת Finish, מוצפנת במפתח הסימטרי שה Client סיפק, הודעה שעוזרת לודא שתהליך העברת המפתח הסימטרי והשימוש בו ע"פ ההצפנה (chiper) הנכונה - הצליח.
נקודה משמעותית לשים לב אליה היא שאם ב HTTP יצירת connection הייתה תקורה של roundtrip אחד בין הדפדפן לשרת, ב HTTPS - התקורה ליצירת connection היא שלושה roundtrips. בתקשורת בין ישראל לארה"ב - מדובר על בערך שנייה (1000ms לפני שהעברנו ביט אחד של מידע בעל-ערך למשתמש).
Session Tickets
אם אתם זוכרים, הדפדפן פותח עד 6 או 8 connections במקביל מול כל שרת בכדי להאיץ את ההורדה.
כדי לא להגיע למצב בו משלמים את התקורה של TLS handshake מספר רב של פעמים, נוספה יכולת בשם Session Ticket (תקן: RFC 5077) המאפשרת ל connection שני, שלישי וכך הלאה, מול אותו השרת, לעשות שימוש חוזר ב: מפתח הסימטרי, אימות, הסכמה-על-הצפנות וכו'.
עם הודעת ה Finish, השרת שולח Session Ticket (מוצפן) ל Client. כל connection חדש יכול לצרף את ה ticket הזה בכדי "להצטרף" ל HTTPS session שמחזיק השרת - ולחסוך לעצמו תהליך handshake נוסף.
בניגוד ל HTTP שבברירת המחדל הוא stateless (מתנתק אחרי כל response), פרוטוקול HTTPS הוא תמיד statefull (במסגרת ה session).
לסיכום: התקורה הנוספת היא בהחלט משמעותית, אבל היא רלוונטית רק לטעינת הדף הראשונית. שרת מודרני (תקן ה Session Ticket הוא מ 2008) ידע לצמצם גם את התקורה הראשונית.
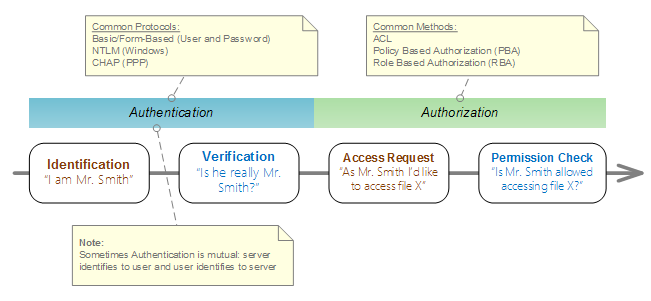
כפי שציינו, פרוטוקול TLS מספק הצפנה + חתימה דיגיטלית - יכולות שאני לא מוצא הרבה מה להרחיב עליהן. בואו נדבר מעט על Authentication.

TLS תמיד כולל אימות של זהות השרת, והשרת יכול לבקש לאמת גם את זהות משתמש הקצה. מנגנון אימות הזהות ( Authentication) למשתמש הקצה הוא תחליפי לשיטות אחרות כגון SAML 2.0 או OpenID.
מנגנון אימות הזהות של TLS מבוסס על שרשרת של אמון, באופן דומה למה שמתרחש בעולם היום-יומי:
כאשר אנו טסים לחו"ל, לא בודקים את זהותנו באופן פרטני - אלא סומכים על מסמך שהנפיקה המדינה שהוא הדרכון שלנו. את הדרכון לא הנפיק חוקר האבטחה הראשי של משרד הפנים באופן אישי - יש לו אמון במשרדים השונים של משרד הפנים הפועלים ברחבי המדינה.
כלומר: משטרת הגבולות (של מדינה זרה, אפילו), סומכת על משרד הפנים, שסומך על משרד כלשהו שבדק את זהותנו בצורה יסודית מספיק והנפיק לנו מסמך קשה-מספיק לזיוף.
TLS משתמש בסטנדרט שנקרא X.509 לתיאור Certificates - "תעודות" המאמתות את זהותו של אדם / שרת.
ישנם Server Certificates לשרתים וישנם Client Certificates לזיהוי משתמשים. בסה"כ אלו מנגנונים דומים.
X.509 מסתמך על היררכיה של Certification Authorities (בקיצור CA) - גופים (לרוב עסקיים) שמורשים להנפיק Certificates. ה CA המוכר ביותר הוא כנראה זה של חברת VeriSign, שחטיבת אימות הזהות שלה נמכרה לפני כשלוש שנים ל Symantec, אך היא עדיין פועלת תחת השם VeriSign.
VeriSign מאמתת זהות של ארגונים ומנפיקה Certificates לשרתים (ליתר דיוק: ל DNS Entries - השרת הוא רק ה"בחור שנמצא שם כרגע"). היא עושה זאת באופן ישיר וגם הרבה בעזרת ספקי משנה שהיא מסמיכה.
הנה הדרך בה תוכלו לבדוק את ה Certificate של אתר אליו אתם גולשים (דוגמה = כרום):

צעדים 1-4 מביאים אותי למסך בו אני רואה את שרשרת (או היררכית) האמון של בנק הפועלים: VeriSign מאמתת זהות של תת-שירות או מחלקה של VeriSign שמאמתת את בנק הפועלים.
VeriSign בהכרח לא תיתן לחברת סטארטאפ מאוקראינה אימות של Bank Haopalim ל DNS שכתובתו www.bankhaopalim.com (זו נראית כמו הכנה להתקפת Phishing! [א]) - צריך להיות קשר ישיר בין השם שנחתם לעסק, ולכתובת ה DNS שאותה מבקשים לחתום.
בפינה הימנית למטה צרפתי עוד דוגמה של Certificate של אתר בשם buy2usa (השייך לחברה buy2) שאומת ע"י CA אחר - במקרה הזה Go Daddy.
ייתכן ותשאלו את עצמכם: מדוע רק לחלק מהאתרים יש רקע ירוק יפה בשם (מסומן בריבוע ירוק בתמונה למעלה)? האם זהו style ב CSS?
ובכן... לא. אתרים שחשובה להם יותר "הפגנת" הזהות שלהם (בנקים זו דוגמה טובה) עוברים תהליך יותר מקיף שנקרא Extended Validation. תהליך אימות הזהות מול ה CA הוא מקיף (ויקר) יותר, אם כי ההצפנה היא אותה ההצפנה.
כלומר: אתם יכולים להיות בטוחים במידה גבוהה יותר של בטחון שמי שבקצה הוא מי שהוא טוען שהוא (כל עוד ההצפנה לא נפרצה).
הנה האופן בו דפדפנים שונים מציגים Extended Validation Certificates:

לכל העניין של חוויית המשתמש יש חשיבות גדולה ב Security - הרי בסוף, אנשים הם חוליה בשרשרת האבטחה. חוליה חלשה - בד"כ.
ספציפית לגבי Extended Validation Certificates (בקיצור: EVC), חוקרים ממייקרוסופט ואוניברסיטת סטנפורד ביצעו מחקר משותף ב 2007 שהראה שמשתמש ממוצע פשוט לא שם לב להדגשה של ה EVC ולא מתייחס אליה כמידע נוסף. מצד שני, אנשים שעברו הדרכה ולמדו לחפש אחרי ההדגשה של ה EVC הצליחו לשים לב אליה ולבצע החלטות טובות יותר בהימנעות מהתקפות phishing.
הנה דוגמה למבנה של Certificate:
הערה: Certificates שמועברים ב HTTPS מקודדים לרוב בפורמט בינרי, ASN.1, כך שלא תראו אותם בפורמט של clear text, כמו זה למעלה.
הנה הצורה בה ה Certificate מוצג בממשק המשתמש של "חלונות":
ציינו שעל מנת לאמת את החתימה הדיגיטלית של ה Certificate, עלינו לפתוח אותו בעזרת המפתח הציבורי של ה CA. מניין לנו המפתח הציבורי של ה CA? כיצד אנו מקבלים אותו בצורה בטוחה ולא "זיוף שלו"?
ובכן, כל הדפדפנים המודרניים מגיעים בהתקנה עם רשימה של Certificates של ה CAs המרכזיים.
במערכת ההפעלה חלונות יש Certificate Store, שזהו אכסון מוצפן של Certificates שמגיעים עם מערכת ההפעלה. כאשר אנו מתקינים או מעדכנים דפדפן - הוא מוסיף ומעדכן Certificates ל Certificate Store. זוהי החלטה של כל דפדפן - על אלו CAs לסמוך.
ניתן לצפות ב Certificate Store בעזרת הפעלה של certmgr.msc מה command line בחלונות.
Root CAs בד"כ חותמים דיגיטלית על עצמם - כלומר בעזרת ה public key שב Certificate ניתן לאמת את החתימה הדיגיטלית.
CAs משניים (Intermediate) חתומים ע"י Root CAs. זו היא בעצם שרשרת האמון עליה דיברנו בתחילת הפוסט.
נחזור לדוגמה שהצגנו מוקדם יותר:

במקרה זה Go Daddy Class 2 הוא ה Root CA שחתם על ה Certificate של עצמו וחתם על Go Daddy Secure - שזהו CA משני (אפילו ששייך לאותה החברה. אולי מדובר בסניף אחר או חטיבה אחרת, למשל).
Go Daddy Secure הוא זה שחתם לנו על buy2 ואימת את זהותו.
בכדי שהדפדפן יאשר את זהותו של buy2, לפחות Certificate אחד בשרשרת צריך להיות trusted (קרי נמצא ב Certs store שלנו), מאומת ותקין.
בהמשך הפוסט נראה מה קורה כאשר Certificate הוא לא תקין.
מעניין לציין של JVM של ג'אווה יש Certificate Store נפרד מזה של מערכת ההפעלה(המורכב מ2 חלקים הנראים truststore ו keystore). ייתכן ויש בו Certificates שונים מאשר בדפדפן. כלומר: אנו יכולים לאמת ישות דרך הדפדפן ולא בעזרת קוד ג'אווה - או להיפך.
אם אתם "חוטפים" שגיאות של javax.net.ssl.SSLException: untrusted server cert chain בעוד אין לבם בעיה להתחבר לאתר עם הדפדפן - יש סיכוי גבוה של JVM אין את ה certificates שיש לדפדפן.
נאמר לי שעורקל נתקלה בבעיה טכנית בגינה היא לא עדכנה certificates בגרסאות הג'אווה זמן מה - אולם לא ראיתי זאת בעצמי.
Client Certificate הוא כזה שמזהה את המשתמש הספציפי, ומשמש לצורך Authentication למערכות שתמוכות בשיטה זו. מאיפה אם כן הוא מגיע למחשב שלכם? האם איי פעם נפגשתם עם סוכן של Go Daddy או VeriSign ונדרשתם להוכיח את זהותכם? - אני מניח שלא.
יש כמה דרכים לייצר Client Certificate:
דרך פשוטה אחת היא בעזרת תוכנה שעושה זאת, ואז אתם חותמים על ה Certificate בעצמכם. למשל הפעלה ב command line של:
תייצר מפתח פרטי בשם server.key ואז הפעלה של
תייצר קובץ certificate על בסיס המפתח שנוצר קודם לכן.
את קובץ ה certificate יש לטעון לשרת בתהליך רישום כלשהו - כדי שיידע להכיר אתכם ולסמוך עליכם. מעתה בחיבור לשרת הזה, לא תצטרכו להקליד שם וססמה - פרוטוקול ה TLS יטפל בעניין.
דרך אחרת היא שהשרת מייצר certificate עבורכם וחותם עליו. אתם מורידים קובץ ועושים לו import לתוך ה Certificate Store.
דרך אחרונה מקובלת היא שארגון ה IT שלכם יוצר לכם certificate ומשתיל אותו בהתקנה / באיזה סקריפט שרץ בהפעלת המחשב.
כמובן שדרך זיהוי זו תקפה בעיקר לזיהוי (Authentication) פנים-ארגוני ולא למערכות אינטרנט, בהן כל תקשורת עוברת דרך תווך לא מאובטח / שקשה לדעת מה מקורו.
לא תמיד הכל הולך כמתוכנן ולפעמים אתר עובד עם HTTPS שנראה תקין... מלבד פרט אחד קטן. הדפדפנים מנסים לשקף למשתמש את מידת הסיכון ע"י חיווי מתאים בממשק המשתמש - חיווי שהם מנסים שיהיה אינטואיטיבי וברור גם למשתמש שלא מכיר את פרוטוקול TLS (קרי: כמעט כל המשתמשים).
עד כמה חיווים אלו ברורים? - תגידו אתם.
אני חושב כדאי להכיר אותם בתור משתמשים "מתקדמים" וגם כדי לענות ללקוח שנתקל בחיווי ופונה אליכם בשאלה "מה לא בסדר?"
לפני שהדפדפן שולח את client certificate לשרת - הוא מבקש את פרטי המשתמש בעזרת dialog (שעשוי להראות מעט שונה בין דפדפנים שונים):
הסיבה לבקשה המפורשת היא שה certificate יכול להכיל כמה פרטים אישיים (שם/שם משפחה, כתובת דואר אלקטרוני) שאיננו רוצים ששרת שהגענו אליו בטעות, ואיננו רוצים באמת להתחבר אליו - יקבל אותם.
ב IE ניתן בעזרת קונפיגורציה לבטל את ה dialog אם יש לנו Client Certificate יחיד מותקן, אולם ככל הידוע לי זהו הדפדפן היחיד שמאפשר זאת.
Mixed Content
ייתכן מצב בו דף HTTPS כולל רכיבים של HTTP. זו איננה בהכרח בעיה, אך זה אומר שהאתר שאנו מתייחסים אליו ברמת בטיחות של HTTPS - הוא לא כזה. התוכן שמגיע ב HTTP יכול להגיע משרת לא מאומת / יכול להיות שעבר שינויים בדרך.
אציין שיש חריגים בכלל של Mixed Content: תגיות img, video, audio ו object שלא כולל data attributes - לא נכללים בבדיקה. מאוד קשה לבצע התקפה עם תמונה - ויש מעט אתרים שמארחים תמונות על גבי HTTPS.
כלומר: אם אנו בונים אתר HTTPS אנו צריכים לוודא שכל ה scripts, css ועוד מגיעים גם ממקורות המאובטחים ע"י HTTPS. זה לא תמיד טריוויאלי.
אם זה לא המצב, הדפדפן יספק משוב למשתמש המזהיר אותו (בדמות משולש צהוב על המנעול, בדפדפן כרום - למשל) שיש איזו פשרה באבטחה.
IE, ולפני כחודשיים בערך החלו גם כרום ו FF לחסום כהתנהגות ברירת-מחדל את תוכן ה HTTP כאשר יש mixed content. כלומר: הדף נטען ללא רכיבי ה HTTP - מה שיכול לגרום לו לרוץ בצורה לא טובה / לא לרוץ בכלל.
למשתמש יש אפשרות אפשרות לבחור שהוא רוצה בכל זאת לטעון את תוכן ה HTTP - מכיוון שהוא מבין את הסיכון ולוקח אותו עליו.
הנה הדרך בה מוצג תוכן חסום והדרך לאפשר אותו בכרום:

והנה ב FF:

לפחות בכרום, אם אני מאפשר תוכן - הדפדפן יזכור את בחירתי ולא יחסום תוכן בעתיד - רק יראה הזהרה.
אם אתם רוצים לבדוק התנהגות של דפדפן אחר, הנה לינק (תקף בעת כתיבת הפוסט) עם תוכן מעורב.
Certificate לא תקין:
כאשר ה Certificate לא תקין, הדפדפן מציג זאת בצורה דיי בולטת:

בעצם, זה נראה דיי מפחיד - וזה יכול לקרות גם לאתר הבטוח שלכם. מספיק שללקוח שלכם אין Certificates מעודכנים של ה CA (כל מיני חברים שרצים על Win XP ו IE7) - וזה מה שהם יקבלו, גם אם האתר שלכם תקין לחלוטין. נדמה לי שפעם הדפדפן היה מגיב בצורה פחות אגרסיבית ל Certificate שהוא פג תוקף - אך זה לא המצב עכשיו.
הנה אתר בו תוכלו למצוא לינקים לדוגמה עם תקלות שונות ב Certificate שלהם: http://testssl.disig.sk/index.en.html
הנה שני אתרים שיכולים לעזור ולנתח מדוע יש תקלת Certificate:
סקרנו את האופציה לבצע Authentication בעזרת HTTPS/TLS על בסיס Certificates וראינו בגדול כיצד המנגנון עובד.
נשארו עוד כמה נושאים שאני רוצה לדון בהם - על ההשלכות היותר קונקרטיות למפתח - אשמור חלק זה לפוסט המשך קצר.
שיהיה בהצלחה!
ההודעה הראשונה שנשלחת ל Client היא הודעת Finish, מוצפנת במפתח הסימטרי שה Client סיפק, הודעה שעוזרת לודא שתהליך העברת המפתח הסימטרי והשימוש בו ע"פ ההצפנה (chiper) הנכונה - הצליח.
Session Tickets
אם אתם זוכרים, הדפדפן פותח עד 6 או 8 connections במקביל מול כל שרת בכדי להאיץ את ההורדה.
כדי לא להגיע למצב בו משלמים את התקורה של TLS handshake מספר רב של פעמים, נוספה יכולת בשם Session Ticket (תקן: RFC 5077) המאפשרת ל connection שני, שלישי וכך הלאה, מול אותו השרת, לעשות שימוש חוזר ב: מפתח הסימטרי, אימות, הסכמה-על-הצפנות וכו'.
עם הודעת ה Finish, השרת שולח Session Ticket (מוצפן) ל Client. כל connection חדש יכול לצרף את ה ticket הזה בכדי "להצטרף" ל HTTPS session שמחזיק השרת - ולחסוך לעצמו תהליך handshake נוסף.
בניגוד ל HTTP שבברירת המחדל הוא stateless (מתנתק אחרי כל response), פרוטוקול HTTPS הוא תמיד statefull (במסגרת ה session).
לסיכום: התקורה הנוספת היא בהחלט משמעותית, אבל היא רלוונטית רק לטעינת הדף הראשונית. שרת מודרני (תקן ה Session Ticket הוא מ 2008) ידע לצמצם גם את התקורה הראשונית.
HTTPS Authentication
כפי שציינו, פרוטוקול TLS מספק הצפנה + חתימה דיגיטלית - יכולות שאני לא מוצא הרבה מה להרחיב עליהן. בואו נדבר מעט על Authentication.
TLS תמיד כולל אימות של זהות השרת, והשרת יכול לבקש לאמת גם את זהות משתמש הקצה. מנגנון אימות הזהות ( Authentication) למשתמש הקצה הוא תחליפי לשיטות אחרות כגון SAML 2.0 או OpenID.
מנגנון אימות הזהות של TLS מבוסס על שרשרת של אמון, באופן דומה למה שמתרחש בעולם היום-יומי:
כאשר אנו טסים לחו"ל, לא בודקים את זהותנו באופן פרטני - אלא סומכים על מסמך שהנפיקה המדינה שהוא הדרכון שלנו. את הדרכון לא הנפיק חוקר האבטחה הראשי של משרד הפנים באופן אישי - יש לו אמון במשרדים השונים של משרד הפנים הפועלים ברחבי המדינה.
כלומר: משטרת הגבולות (של מדינה זרה, אפילו), סומכת על משרד הפנים, שסומך על משרד כלשהו שבדק את זהותנו בצורה יסודית מספיק והנפיק לנו מסמך קשה-מספיק לזיוף.
TLS משתמש בסטנדרט שנקרא X.509 לתיאור Certificates - "תעודות" המאמתות את זהותו של אדם / שרת.
ישנם Server Certificates לשרתים וישנם Client Certificates לזיהוי משתמשים. בסה"כ אלו מנגנונים דומים.
X.509 מסתמך על היררכיה של Certification Authorities (בקיצור CA) - גופים (לרוב עסקיים) שמורשים להנפיק Certificates. ה CA המוכר ביותר הוא כנראה זה של חברת VeriSign, שחטיבת אימות הזהות שלה נמכרה לפני כשלוש שנים ל Symantec, אך היא עדיין פועלת תחת השם VeriSign.
VeriSign מאמתת זהות של ארגונים ומנפיקה Certificates לשרתים (ליתר דיוק: ל DNS Entries - השרת הוא רק ה"בחור שנמצא שם כרגע"). היא עושה זאת באופן ישיר וגם הרבה בעזרת ספקי משנה שהיא מסמיכה.
הנה הדרך בה תוכלו לבדוק את ה Certificate של אתר אליו אתם גולשים (דוגמה = כרום):

צעדים 1-4 מביאים אותי למסך בו אני רואה את שרשרת (או היררכית) האמון של בנק הפועלים: VeriSign מאמתת זהות של תת-שירות או מחלקה של VeriSign שמאמתת את בנק הפועלים.
VeriSign בהכרח לא תיתן לחברת סטארטאפ מאוקראינה אימות של Bank Haopalim ל DNS שכתובתו www.bankhaopalim.com (זו נראית כמו הכנה להתקפת Phishing! [א]) - צריך להיות קשר ישיר בין השם שנחתם לעסק, ולכתובת ה DNS שאותה מבקשים לחתום.
בפינה הימנית למטה צרפתי עוד דוגמה של Certificate של אתר בשם buy2usa (השייך לחברה buy2) שאומת ע"י CA אחר - במקרה הזה Go Daddy.
ייתכן ותשאלו את עצמכם: מדוע רק לחלק מהאתרים יש רקע ירוק יפה בשם (מסומן בריבוע ירוק בתמונה למעלה)? האם זהו style ב CSS?
ובכן... לא. אתרים שחשובה להם יותר "הפגנת" הזהות שלהם (בנקים זו דוגמה טובה) עוברים תהליך יותר מקיף שנקרא Extended Validation. תהליך אימות הזהות מול ה CA הוא מקיף (ויקר) יותר, אם כי ההצפנה היא אותה ההצפנה.
כלומר: אתם יכולים להיות בטוחים במידה גבוהה יותר של בטחון שמי שבקצה הוא מי שהוא טוען שהוא (כל עוד ההצפנה לא נפרצה).
הנה האופן בו דפדפנים שונים מציגים Extended Validation Certificates:

לכל העניין של חוויית המשתמש יש חשיבות גדולה ב Security - הרי בסוף, אנשים הם חוליה בשרשרת האבטחה. חוליה חלשה - בד"כ.
ספציפית לגבי Extended Validation Certificates (בקיצור: EVC), חוקרים ממייקרוסופט ואוניברסיטת סטנפורד ביצעו מחקר משותף ב 2007 שהראה שמשתמש ממוצע פשוט לא שם לב להדגשה של ה EVC ולא מתייחס אליה כמידע נוסף. מצד שני, אנשים שעברו הדרכה ולמדו לחפש אחרי ההדגשה של ה EVC הצליחו לשים לב אליה ולבצע החלטות טובות יותר בהימנעות מהתקפות phishing.
אז מהם בדיוק ה Certificates ואיך הם מבטיחים וידוא אמין של זהות?
- Certificate הוא צירוף של Public Key (א-סימטרי), זיהוי הישות, וכמה שדות מידע אחרים.
- Certificate נחתם בחתימה דיגיטלית, לפחות בעזרת המפתח הפרטי העצמי.
- X.509 Certificate הוא תקן שמכיל כמה שדות סטנדרטיים ומאפשר הרחבה לשדות נוספים - ללא הגבלות מסוימות על אורך / מבנה המידע.
- Certificates נקראים לעתים בקיצור certs, בעיקר בפורומים מקצועיים של אבטחה.
הנה דוגמה למבנה של Certificate:
 |
| מקור: וויקיפדיה |
הערה: Certificates שמועברים ב HTTPS מקודדים לרוב בפורמט בינרי, ASN.1, כך שלא תראו אותם בפורמט של clear text, כמו זה למעלה.
- Issuer זו הסמכות שאימתה את זהות השרת/משתמש, ה CA.
- כל Certificate מגיע עם תאריך תפוגה - ולא יהיה תקין אם תאריך זה חלף.
- אלו פרטי הישות שאותה ה Certificate מזהה. הרשומה החשובה ביותר היא ה CN (קיצור של Common Name, ע"פ פרומט X.501, כזה המוכר לכם אולי מ LDAP) שצריכה להתאים ל DNS Entry, במידה ומדובר בשרת.
- זהו המפתח הציבורי של הישות המזוהה.
- זוהי חתימה דיגיטלית שנוצרה על בסיס MD5 (פונקציית גיבוב) של כל ההודעה - ונחתמה ע"י המפתח הפרטי של ה CA (או חותם אחר: חתימה עצמית או ארגון). כדי לפתוח אותה המשתמש זקוק למפתח הציבורי של ה CA.
הנה הצורה בה ה Certificate מוצג בממשק המשתמש של "חלונות":
 |
| הערה: certificate זה לא מתואם עם הדוגמה מוויקיפדיה - הוא חדש הרבה יותר |
מהיכן מגיעים Server Certificates למחשב?
ציינו שעל מנת לאמת את החתימה הדיגיטלית של ה Certificate, עלינו לפתוח אותו בעזרת המפתח הציבורי של ה CA. מניין לנו המפתח הציבורי של ה CA? כיצד אנו מקבלים אותו בצורה בטוחה ולא "זיוף שלו"?
ובכן, כל הדפדפנים המודרניים מגיעים בהתקנה עם רשימה של Certificates של ה CAs המרכזיים.
במערכת ההפעלה חלונות יש Certificate Store, שזהו אכסון מוצפן של Certificates שמגיעים עם מערכת ההפעלה. כאשר אנו מתקינים או מעדכנים דפדפן - הוא מוסיף ומעדכן Certificates ל Certificate Store. זוהי החלטה של כל דפדפן - על אלו CAs לסמוך.
ניתן לצפות ב Certificate Store בעזרת הפעלה של certmgr.msc מה command line בחלונות.
Root CAs בד"כ חותמים דיגיטלית על עצמם - כלומר בעזרת ה public key שב Certificate ניתן לאמת את החתימה הדיגיטלית.
CAs משניים (Intermediate) חתומים ע"י Root CAs. זו היא בעצם שרשרת האמון עליה דיברנו בתחילת הפוסט.
נחזור לדוגמה שהצגנו מוקדם יותר:
במקרה זה Go Daddy Class 2 הוא ה Root CA שחתם על ה Certificate של עצמו וחתם על Go Daddy Secure - שזהו CA משני (אפילו ששייך לאותה החברה. אולי מדובר בסניף אחר או חטיבה אחרת, למשל).
Go Daddy Secure הוא זה שחתם לנו על buy2 ואימת את זהותו.
בכדי שהדפדפן יאשר את זהותו של buy2, לפחות Certificate אחד בשרשרת צריך להיות trusted (קרי נמצא ב Certs store שלנו), מאומת ותקין.
בהמשך הפוסט נראה מה קורה כאשר Certificate הוא לא תקין.
 |
| שרשרת האמון ב certificates. מקור: איליה גריגוריק |
מעניין לציין של JVM של ג'אווה יש Certificate Store נפרד מזה של מערכת ההפעלה(המורכב מ2 חלקים הנראים truststore ו keystore). ייתכן ויש בו Certificates שונים מאשר בדפדפן. כלומר: אנו יכולים לאמת ישות דרך הדפדפן ולא בעזרת קוד ג'אווה - או להיפך.
אם אתם "חוטפים" שגיאות של javax.net.ssl.SSLException: untrusted server cert chain בעוד אין לבם בעיה להתחבר לאתר עם הדפדפן - יש סיכוי גבוה של JVM אין את ה certificates שיש לדפדפן.
נאמר לי שעורקל נתקלה בבעיה טכנית בגינה היא לא עדכנה certificates בגרסאות הג'אווה זמן מה - אולם לא ראיתי זאת בעצמי.
מהיכן מגיע Client Certificate למחשב?
Client Certificate הוא כזה שמזהה את המשתמש הספציפי, ומשמש לצורך Authentication למערכות שתמוכות בשיטה זו. מאיפה אם כן הוא מגיע למחשב שלכם? האם איי פעם נפגשתם עם סוכן של Go Daddy או VeriSign ונדרשתם להוכיח את זהותכם? - אני מניח שלא.
יש כמה דרכים לייצר Client Certificate:
דרך פשוטה אחת היא בעזרת תוכנה שעושה זאת, ואז אתם חותמים על ה Certificate בעצמכם. למשל הפעלה ב command line של:
openssl genrsa -des3 -out server.key 1024
openssl req -new -key server.key -out my_cert.csr
תייצר קובץ certificate על בסיס המפתח שנוצר קודם לכן.
את קובץ ה certificate יש לטעון לשרת בתהליך רישום כלשהו - כדי שיידע להכיר אתכם ולסמוך עליכם. מעתה בחיבור לשרת הזה, לא תצטרכו להקליד שם וססמה - פרוטוקול ה TLS יטפל בעניין.
דרך אחרת היא שהשרת מייצר certificate עבורכם וחותם עליו. אתם מורידים קובץ ועושים לו import לתוך ה Certificate Store.
דרך אחרונה מקובלת היא שארגון ה IT שלכם יוצר לכם certificate ומשתיל אותו בהתקנה / באיזה סקריפט שרץ בהפעלת המחשב.
כמובן שדרך זיהוי זו תקפה בעיקר לזיהוי (Authentication) פנים-ארגוני ולא למערכות אינטרנט, בהן כל תקשורת עוברת דרך תווך לא מאובטח / שקשה לדעת מה מקורו.
התנהגות הדפדפן וחיווי למשתמש
לא תמיד הכל הולך כמתוכנן ולפעמים אתר עובד עם HTTPS שנראה תקין... מלבד פרט אחד קטן. הדפדפנים מנסים לשקף למשתמש את מידת הסיכון ע"י חיווי מתאים בממשק המשתמש - חיווי שהם מנסים שיהיה אינטואיטיבי וברור גם למשתמש שלא מכיר את פרוטוקול TLS (קרי: כמעט כל המשתמשים).
עד כמה חיווים אלו ברורים? - תגידו אתם.
אני חושב כדאי להכיר אותם בתור משתמשים "מתקדמים" וגם כדי לענות ללקוח שנתקל בחיווי ופונה אליכם בשאלה "מה לא בסדר?"
לפני שהדפדפן שולח את client certificate לשרת - הוא מבקש את פרטי המשתמש בעזרת dialog (שעשוי להראות מעט שונה בין דפדפנים שונים):
 |
| חלון אישור לשליחת Client Certificate בכרום |
ב IE ניתן בעזרת קונפיגורציה לבטל את ה dialog אם יש לנו Client Certificate יחיד מותקן, אולם ככל הידוע לי זהו הדפדפן היחיד שמאפשר זאת.
Mixed Content
ייתכן מצב בו דף HTTPS כולל רכיבים של HTTP. זו איננה בהכרח בעיה, אך זה אומר שהאתר שאנו מתייחסים אליו ברמת בטיחות של HTTPS - הוא לא כזה. התוכן שמגיע ב HTTP יכול להגיע משרת לא מאומת / יכול להיות שעבר שינויים בדרך.
אציין שיש חריגים בכלל של Mixed Content: תגיות img, video, audio ו object שלא כולל data attributes - לא נכללים בבדיקה. מאוד קשה לבצע התקפה עם תמונה - ויש מעט אתרים שמארחים תמונות על גבי HTTPS.
כלומר: אם אנו בונים אתר HTTPS אנו צריכים לוודא שכל ה scripts, css ועוד מגיעים גם ממקורות המאובטחים ע"י HTTPS. זה לא תמיד טריוויאלי.
אם זה לא המצב, הדפדפן יספק משוב למשתמש המזהיר אותו (בדמות משולש צהוב על המנעול, בדפדפן כרום - למשל) שיש איזו פשרה באבטחה.
 |
| ההזהרה, כפי שנראית בעת כתיבת הפוסט בכרום |
IE, ולפני כחודשיים בערך החלו גם כרום ו FF לחסום כהתנהגות ברירת-מחדל את תוכן ה HTTP כאשר יש mixed content. כלומר: הדף נטען ללא רכיבי ה HTTP - מה שיכול לגרום לו לרוץ בצורה לא טובה / לא לרוץ בכלל.
למשתמש יש אפשרות אפשרות לבחור שהוא רוצה בכל זאת לטעון את תוכן ה HTTP - מכיוון שהוא מבין את הסיכון ולוקח אותו עליו.
הנה הדרך בה מוצג תוכן חסום והדרך לאפשר אותו בכרום:

לפחות בכרום, אם אני מאפשר תוכן - הדפדפן יזכור את בחירתי ולא יחסום תוכן בעתיד - רק יראה הזהרה.
אם אתם רוצים לבדוק התנהגות של דפדפן אחר, הנה לינק (תקף בעת כתיבת הפוסט) עם תוכן מעורב.
Certificate לא תקין:
כאשר ה Certificate לא תקין, הדפדפן מציג זאת בצורה דיי בולטת:

הנה אתר בו תוכלו למצוא לינקים לדוגמה עם תקלות שונות ב Certificate שלהם: http://testssl.disig.sk/index.en.html
הנה שני אתרים שיכולים לעזור ולנתח מדוע יש תקלת Certificate:
סיכום
פו.... זו הייתה כתיבה ארוכה!סקרנו את האופציה לבצע Authentication בעזרת HTTPS/TLS על בסיס Certificates וראינו בגדול כיצד המנגנון עובד.
נשארו עוד כמה נושאים שאני רוצה לדון בהם - על ההשלכות היותר קונקרטיות למפתח - אשמור חלק זה לפוסט המשך קצר.
שיהיה בהצלחה!
----
[א] נשמע כמו "לדוג", אבל הכוונה היא להתחזות למקור אמין בכדי לגנוב פרטים או את זהות המשתמשים.
[א] נשמע כמו "לדוג", אבל הכוונה היא להתחזות למקור אמין בכדי לגנוב פרטים או את זהות המשתמשים.