ריילס, או בשמה המלא Ruby On Rails (קיצור מקובל: ROR) היא מסגרת פיתוח (Framework) פופולרית לבניית אפליקציות ווב.

ההחלטה התכנונית המרכזית של ריילס, אם כן, היא "פריון (productivity) על פני גמישות".
רובי, כתכונה של השפה מאפשרת (ומעודדת) שימוש ב metaprogramming בכדי להרחיב את השפה עצמה וליצור DSLs חדשים. יכולות אלו, הן אולי הסיבה המרכזית שריילס הצליחה להיות יותר אפקטיבית [א] מספריות ווב אחריות (ASP.NET MVC, Lavarel או !Play) - שהיו משוחררות גם הן מ"כבלי ארכיטקטורת ה Enterprise של JEE". פקודות שימושיות בכתיבה של אפליקציות ריילס (למשל הגדרות שונות על המודל) הן בעצם הרחבות של ריילס לשפת רובי. מתכנת ריילס ללא רקע משמעותי ברובי עשוי לא להיות מסוגל להבחין אלו תכונות בהן הוא משתמש שייכות לשפת רובי - ואלו שייכות לריילס (ואולי גם לא ממש אכפת לו).
תכונה אחרונה של ריילס שארצה לציין היא "בדיקתיות". יוצרי ריילס (ממש כמו יוצרי AngularJS, למשל) היו מודעים היטב לצורך בבדיקות - והם בנו תשתית שמאפשרת לבדוק את הקוד שרץ עליה בקלות יחסית. בדיקות יחידה ואינטגרציה הן חלק מובנה מריילס, ו flows הבדיקה מאופשרים היטב בכל הרמות , אם כי קצת יותר לכיוון ה integration tests וקצת פחות לכיוון ה isolated unit tests. כמות ספריות הבדיקה הזמינה לשפת רובי היא מרשימה (RSpec, MiniTest, Test::Unit, Cucumber, Factory_girl), ולכמה מהספריות הללו יש הרחבות מיוחדות לריילס (למשל Rspec_rails או Factory_girl_rails). בדיקות הוא לא רעיון זר בקהילת הרובי או ה RoR...
מעניין לציין שדווקא DHH הוא זה בשנה האחרונה העלה כמה דברי ביקורת על כתיבת בדיקות. בגלל ש DHH קידם מאוד את תרבות כתיבת הבדיקות (וגם בגלל שהוא הגורו הבלתי-מערוער בעולם של ריילס?) - דבריו זכו לתהודה רבה. הוא כתיב פוסט בשם Test-induced design damage, ואח"כ העביר סשן בשם "?Is TDD Dead". בסוף הפוסט תוכלו למצוא לינק לסדרת הסשנים המעניינת בה הפגישו אותו עם יוצר ה TDD (קנט בק) ומרטין פאוולר (ששימש כמגשר?). סדרה של 3 שעות - אך בהחלט מעניינת.
אם אתם מחפשים את החלופה "העכשווית" לריילס שתוכננה במקור לקוד צד-לקוח משמעותי, ו MongoDB - אתם כנראה מחפשים את MeteorJS (עם כל היתרונות, וגם החסרונות שלה).
אכן נראה שחלק ממפתחי הריילס (כלומר: רובי + ריילס) עוזבים את ריילס ומחפשים Frameworks חדשים לעבוד איתם. הטיעון ששמעתי כבר כמה פעמים הוא "אני לא רואה הגיון לעשות MVC גם בשרת וגם בצד הלקוח" (ברור שלא! מוזר לשמוע בכלל ניסו כזה דבר). באופן טבעי, חלקם מחפשים את המוכר, ולא מפתיע למוצא frameworks שמנסים לספק את הצורך הזה. קשה לי שלא לציין את Sails - של node.js ו grails של שפת גרובי (groovy). האחרון הוא לא חדש - אבל קשה להתעלם מהצליל המוכר שהוא בחר לעצמו :)
המודל - שומר את ה state של המערכת (בעזרת בסיס הנתונים, אם כי לפעמים רק בזכרון), אוכף "חוקים עסקיים" על נכונות ה data (למשל: סטודנט חייב להיות רשום לתוכנית לימודים כלשהי). הוא לא בהכרח המאמת היחידי של הנתונים, אלא ה gatekeeper לפני שהמידע נשמר / משותף עם חלקים אחרים במערכת. בניגוד ל MVC של Smalltalk הוא גם כולל חלק מהלוגיקה - ראו בהמשך את ההסבר על Active Records.
המודל, בגדול - הוא זמין לכלל האפליקציה, אין בו partitioning (או bounded context).
ה View - הוא הקוד שמייצר דפי HTML למשתמש, על בסיס מידע במודל. ריילס היא תשתית לכתיבת MVC בצד-השרת (כלומר: השרת מייצר HTML, ומוסיף JavaScript לאינטרקטיביות). בדומה למודל ה MVC הקלאסי ה View לא מקבל input מהמשתמש, ולא מנהל איתו שום סוג של אינטרקציה (לפחות לא בצד-השרת).
ה controller - אחראי לקבלת קלט מהמשתמש, טיפול בו, ותפעול (ניתן לומר: orchestration) של המערכת עד שהמשתמש מקבל בחזרה את התשובה שלו. דרך העבודה שלו היא לעדכן את המודל, ואז להזניק את ה View המתאים (הוא לא מעביר מידע ל view ישירות).
בריילס יש גם routers - שהם ממפים URLs, ומצבים - ל Views. לדוגמה: אם משתמש שהוא admin ניגש לדף מסוים - הוא יקבל View אחר ממשתמש רגיל. ה router עושה מה שבמערכות אחרות עושה סוג של "super controller". הוא דקלרטיבי, בעזרת סט של ״פקודות״ מיוחדות לעניין (מה שהופך אותו לפשוט יותר לכתיבה ותחזוקה) - וסה"כ הוא מהווה הרחבה מבורכת על מודל ה MVC ה"קלאסי".
רכיבים עיקריים של ריילס הם:
Active Records (בקיצור: AR)
כלי ה lightweight ORM של רובי, המנהל בפועל את הגישה לבסיס הנתונים של המודל. רובי מספקת גם כלים להגדרת טבלאות ברובי דקלרטיבי (ולא SQL, על הווריאנטים תלויי בסיס הנתונים הספציפי שלו) וכלים מובנים לביצוע migrations בין גרסאות שונות לסכמת בסיס הנתונים (מה שמקובל בג׳אווה לעשות עם flyway).
השם "Active Records" הוא בעצם של שם של דפוס-עיצוב (מופיע בספר PoEAA) אותו המודול מממש.
דפוס העיצוב "Active Record" מגדיר מחלקה בשפה (במקרה שלנו: רובי) שמתארת נתונים של שורה (להלן Record) בבסיס הנתונים, אבל מוסיפה עליהם גם את התנהגות ה domain הרלוונטית לאותם נתונים (להלן Active). למשל: validation, חישובים, derived fields, וכו'. הבהרה: יש מחלקה אחת לכל טבלה, ומייצרים מופעים שלה ע"פ הרשומות להם נזקקים באותו הרגע.
דפוס עיצוב זה מרשה לערבב בין מיפוי הנתונים בין בסיס הנתונים לזיכרון, עם לוגיקה עסקית - כל עוד הלוגיקה העסקית היא רק ברמה של הרשומה הבודדת (ולא "שייכת" ל scope רחב יותר). ערבוב זה, נמצא בוויכוח תמידי על הלגיטימיות שלו, מכיוון שהוא סותר כלל מקובל בארכיטקטורה הנפוצה ביותר למערכות מבוססות-נתונים (הרי היא Layered Architecture) - הפרדה בין Persistence ל Business Logic, או בצורת דפוס העיצוב "Data Mapper" אותה מממשים רוב כלי ה ORM המוכרים - הפרדה מוחלטת בין לוגיקה עסקית למיפוי הנתונים בין בסיס הנתונים לזיכרון [ו].
בריילס, יידרש מאמץ מיוחד בכדי לא-לעבוד עם Active Records, אז כדאי שתתנו לדפוס זה הזדמנות - גם אם כל חייכם "גדלתם" על Data Mappers ;-).
Active Records מאפשר לנו לכתוב אובייקט "פשוט" ברובי, לרשת מ ActiveRecord::Base ולקבל את פעולות ה CRUD הבסיסיות ע"י סיפוק הגדרות בסיסיות של מה שאנו רוצים (declarative programming).
לא! זה לא "בחינם", אין ארוחות-חינם בהנדסת תוכנה. אנו מוותרים על גמישות וקצת על ביצועים - בכדי לקבל את הנוחות הזו.
Active Records מכתיב כללים מוסכמים לשמות - בכדי לצמצם את הצורך בהגדרות דומות, בכל פעם מחדש.
למשל: שם הטבלה בבסיס הנתונים צריך להתאים לשם המחלקה (בוריאציה מסוימת), וכן שמות ה primary key וה foreign_keys, ועוד. פרטים על כללי השמות - אספק בהמשך הפוסט. אפשר שתהיה חוסר התאמה בשמות - אבל אז צריך לכתוב קונפיגורציה לכך.
את שאר הרכיבים אזכיר בקצרה, לא כי הם פחות חשובים, אלא בגלל שנדרש ידע נוסף בריילס על מנת להבין אותם.
כל עבודת ה low-level ברמת ה HTTP הוא לא חלק מריילס. חלק זה יטופל ברמת ה Application Server - עליו נדבר בהמשך.
כחלק מה Convention over Configuration, לאפליקציית ריילס יש מבנה תיקיות מוסכם-מראש. בכדי ליצור מבנה זה יש להקליד בשורת הפקודה:
d- הוא פרמטר שמגדיר באיזה בסיס נתונים אתם הולכים להשתמש - והוא יחסוך לכם יצירה של כמה קונפיגוריות בצורה ידנית מאוחר יותר.
התיקיות המעניינות ביותר באפליקציית הריילס הן תיקיות ה app, config, ו lib. אם יש בדיקות טובות - הוסיפו לכך (במקום גבוה) את תיקיית ה tests (לפעמים תראו אותה בשם spec).
תיקיית ה bin כוללת את הסקריפטים לפעולות הבסיסיות של האפליקציה. אלו בעצם wrapper scripts (נקראים ברובי גם binstubs) שרק מכינים את סביבת הריצה ואז קוראים ל executable הנכון. לפני ריילס גרסה 4 קראו לתיקיה זו בשם "scripts".
קובץ ה Gemfile (מתחיל באות גדולה) הוא קובץ של כלי רובי בשם bundler, כלי שעוזר להגדיר, ואז להתקין - תלויות (gems [ב]) על סביבות חדשות בהן תרוץ האפליקציה.
ברגע שמריצים את הפקודה "bundle install", אז bundler יקרא את קובץ ה Gemfile, יבדוק מהן הספריות הנדרשות וגרסאותיהן, ויתקין את מה שלא נמצא - בגרסאות המתאימות. אם אתם מכירים את קובץ ה package.json של node.js - זה ממש אותו הדבר.
קובץ ה Gemfile שנוצר בעקבות הפקודה "rails new" כולל כבר רשימה של ספריות שימושיות: דרייבר לבסיס הנתונים שהגדרתם, כמה ספריות צד-לקוח, ספרייה ל generation של תיעוד, ספריה לעבודה עם JSON, וכו'.
Gemfile.lock הוא קובץ בו bundler מנהל לעצמו את הגרסאות שמותקנות בפועל. זהו קובץ שתרצו להכניס ל git repository שלכם - אך לא לשנות ידנית (אין קשר לקבצי lock של MS Office, שמטפלים ב concurrency).
קובץ ה rakefile הוא של כלי ה build של רובי שנקרא rake. ה build ברובי כולל בעיקר בדיקות, פענוח הסכמה, Linting, וטיפול בקצבי HTML ו CSS (למשל: minification).
קובץ ה rakefile של ריילס יהיה לרוב מינימלי, והדבר המרכזי שהוא יעשה הוא לטעון ולהריץ רשימה של rake tasks (שאתם תכתבו). קבצי ה task יושבים בתיקיה lib/tasks.
בריילס, עובדים לא מעט עם command line עבור scaffolding [ג]: ניהול בסיס הנתונים, ביצוע buid, הרצת האפליקציה, ועוד.
לפעמים הפקודות הללו לא עובדות כראוי, ו"טריק" מקובל הוא לקרוא ל <bundle exec rake <rake params - מה שהופך את כל ה gems שמצוינים ב Gemfile לזמינים, אפילו אם הם לא ב path של מערכת ההפעלה.
התיקייה lib, ע"פ הגדרה אחת, כוללת קוד שהוא לא מודל, controller, router, או View.
התיקייה lib, ע"פ הגדרה נוספת, כוללת קוד שניתן לעשות שימוש חוזר בו בין הרכיבים השונים (view, model, controller).
מלבד כמה תתי ספריות נדרשות (למשל tasks) - יש לכם חופש כיצד לארגן אותה.
בגרסאות ישנות של ריילס, כל הקבצים שישבו ב lib נטענו כזמינים לכל הרכיבים במערכת. כלל זה שונה והיום עליכם להדיר במפורש באיזה lib רכיב ה app שלכם רצה להשתמש - בכדי להשתמש בו. ( או פשוט להוסיף ל config/application.rb את הפקודה config.autoload_paths += %W(#{Rails.root}/lib שתעשה מה שריילס עשתה בגרסאות ישנות).
נוהגים לומר שהקהילה של ריילס "התבגרה" בשנים האחרונות. ריילס "ניסתה לדלג" על כל מיני כללים מקובלים של הנדסת תוכנה בכדי להאיץ את קצב הפיתוח. חלק מהדילוגים הללו הוכחו כבעייתיים - ואז ריילס חזרה בה (נראה לי שהמקרה הנ״ל הוא אחד כזה). דילוגים אחרים - אולי הוכחו כלא בעייתיים, בהקשרים בהם ריילס עובדת. אני זוכר ששמעתי דיונים על כך בקהילת הג'אווה לפני מספר שנים: "הנה ריילס מתבגרת, והחברה שם עושים היום יותר ויותר הנדסת תוכנה כמו ג'אווה". המסקנה שהוסקה (שגם לי נראתה הגיונית, בזמנו) הייתה ש"ג'אווה צדקה" (שהחילה על עצמה כל כלל אפשרי של הנדסת תוכנה) - וריילס "בדרך להיות סוג של ג'אווה".
נו טוב, סתם רכילות cross-קהילתית.
שני קבצים חשובים שנטענים בעליה של ריילס הם config/environement.rb ו config/application.rb.
בנוסף תמצאו בתיקיה config/environemnts קובץ קונפיגורציה לכל סוג סביבה: development, production ו test - זה הבסיס למערכת ה staging של ריילס.
כשמפעילים את אפליקציית הריילס, ניתן לציין את הסביבה כפרמטר, למשל:
בכדי לטעון קונפיגורציה לסביבת ה staging המתאימה.
זהו.
ייתכן ותתקלו בקבצים ריקים בשם ״keep.״. מטרתם היא למנוע מכלים מסוימים להתעלם מהתיקיות שנוצרו ע"י "rails new" - וניתן (ומומלץ) למחוק אותם כאשר התיקיה מתמלאה בתוכן. חבל לראות פרויקט ריילס בן כמה שנים - שעדיין שמר את הקבצים הללו.
הפעלת האפליקציה נעשית ע"י פקודת "rails server", או בקיצור "rails s".
כל אפליקציית ריילס רצה על "שרת ווב משלה", בתוך תהליך של מערכת ההפעלה. ניהול של כמה אפליקציות על אותו שרת פיסי, מתרחשת ע"י הפעלה של כמה "תהליכי שרת", אולי מסוגים שונים ו/או גרסאות שונות.
ריילס מגיע כברירת מחדל עם שרת "רזה" בשם WEBrick. זהו שרת פשוט למדי - שמשמש בעיקר לצורכי פיתוח (ולא ל production). ב Production מקובל להשתמש ב Puma, Raptor או ב Unicorn.
Rack הוא שמה של הספציפיקציה של שרת ווב ברובי, וגם השם של ה Reference Implementation שלה.
Rack דומה בתפקידו ל Servlet API של ג'אווה, שבמקרה יש לו גם מימוש באותו השם (דמיינו ש Tomcat נקרא "Servlet"). החלק החשוב יותר של Rack הוא הספסיפיקציה. כנראה שהחבר'ה של רובי ראו מה קרה בעולם של פייטון, שבו לא היה תקן שכזה, וכל שרת ווב עושה את אותו הדבר - אבל מגדיר זאת אחרת.
סה"כ ה API ש Rack מציע הוא מאוד בסיסי: הוא עובד ברמת הפשטה מאוד נמוכה - ה HTTP Request-Response Lifecycle (בדומה ל CGI - אם אתם ותיקים מספיק בכדי לדעת מה זה).
מצד מימושי השרת, המימושים הנפוצים ביותר הם Rack (כמובן), Unicorn, או Mongrel.
ספסיפקציית ה Rack משתמש לא רק את RoR, אלא גם Frameworks אחרים כגון Sinatra, Ramaze ו Merb (שמוזג לתוך RoR בגרסה 3.0).
כמה מלים על Rack כ reference implementation:
מקור השם Rack הוא הכוננית בחדר השרתים שעליה מתקינים את השרתים / ציוד הרשת. יוצריו בחרו בשם זה בגלל מנגנון ה plugins שלו, שמאפשר למודולים צד שלישי (הנקראים middleware, דומים ל Servlet Filters בג'אווה) להרחיב אותו בקלות. הנה רשימה של מודולים זמינים.
מעניין להזכיר את Rack::MockRequest שמייצר mocks לאובייקטי request ו response (נחמד שזה מגיע מ"הספק"), ו Rack::Lint שעושה Linting על קוד המשתמש ב API של Rack ומוצא כמה common pitfalls.
קובץ הקונפיגורציה של Rack, הנקרא config.ru מכיל את ההגדרה של ה middlewares שאנו משתמשים בהם, ו metals.
Rails Metal Apps (בקיצור: metal, מלשון "bare-metal" - אני מניח) הן חתיכות קוד באפליקציית הריילס שלנו, שירוצו ישירות מעל ה API של Rack, ללא תוספות.
מדוע לעשות זאת? בגלל ביצועים, למשל: כדי לספק REST API שקוראים לו בקצב מהיר.
ה stack של ריילס שמריץ את ה controllers (ה Action Controller Stack) מציב תקורה משמעותית לכל request שמטופל. אם אנו רוצים לספק תשובה פשוטה, ולעשות זאת מהר - כדאי לעקוף אותו.
הערה: ברור שאם אנו זקוקים לביצועים ממש גבוהים - גם metal עדיין מציב מגבלה על מה שאפשר להשיג מהחומרה. שפת רובי היא לא concurrent (השתפרה, אבל עדיין לא ממש) ואין לה parallelism. כדי להגיע ל throughput או tps גבוה במיוחד - כדאי לשקול עבודה נקודתית עם node.js (עבור קוד "רעב" ל I/O) או עבודה ב Go (עבור קוד "רעב" ל CPU) [ד].
אחרונה חביבה, היא ספרייה בשם spring שעובדת עם rake (שהיא כבר חלק מובנה מריילס 4.1 ומעלה) שעושה preloading לשינויים באפליקציית הריילס מבלי לעשות restart לשרת (אלא על בסיס של fork של ה process - לא עובד ב Windows או ב JRuby). יכולת דומה קיימת באופן מובנה בשרת ה Unicorn.

כפי שהזכרנו כבר קודם לכן, ריילס מציגה כללי naming שאם תעבדו לפיהם - תצטמצם מאוד כמות הקונפיגורציה שתצטרכו לנהל. בפועל - דרך העבודה המקובלת בריילס היא להצמד באופן מוחלט ל conventions, בכדי להימנע מניהול קונפיגורציות עד כמה שניתן.
בכדי להבין את ה conventions, אזכיר שאנו נמצאים ברובי - ולכן על ריילס היה להתאים את עצמה גם ל conventions של רובי (אותם סקרתי בפוסט שפת Ruby - מה זה השטויות האלה?!).
שמות של טבלאות בבסיס הנתונים יהיו ב snake_case - כמו משתנים. טבלאות תמיד יקראו ע"פ צורת הרבים של האובייקט (plural): למשל People או Invoices ולא Person או Invoice.
למה? כדי שהקוד יהיה קרוב יותר לשפה הטבעית: "Select a Product from products". אני מניח שהבדל זה יכול גם להקל להבחין מהר בין מחלקה לטבלה בבסיס הנתונים.
שמות של קבצים (model, view, controller, וכו') יהיו גם הם ב snake_case - כפי שמקובל ברובי גם מחוץ לריילס.
נניח שאנו רוצים ליצור מודל בשם LineItem (שם מחלקה ברובי הוא CamelCase). כדי שהכל יעבוד, ללא קונפיגורציה נוספת, על שם הקובץ המכיל את המחלקה להיות line_item.rb (והיא תהיה בתיקייה app/models), ועל שם הטבלה בבסיס הנתונים להיות line_items.
"אני מבין איך עושים זאת עבור line_items, אבל איך *לעזאזל* ריילס תקשר עבורי בין people ל person?". שאלה טובה. הציצו ב utility של ActiveSupport שעושה זאת: inflections.rb. הוא מכיר יוצאי-דופן מוכרים כמו person-people או octopus-octupi, ואתם גם יכולים ללמד אותו כללים חדשים, למשל: selfie-selfieez.
ל controllers יש כללים נוספים:
אם יש לנו Controller ששם המחלקה שלו הוא InvoiceController, אז עליו להיות בקובץ בשם invoice_controller.rb שנמצא בתיקייה app/controllers. עד כאן - זה כמו המודלים.
בנוסף, ריילס תצפה שיהיה קובץ נוסף בשם invoice_helper.rb בתיקייה app/helpers שיכיל מחלקה בשם InvoiceHelper.
ריילס גם תצפה שה view templates של ה controller הזה יהיו בתיקיה בשם apps/views/invoice. כהתנהגות ברירת מחדל, ריילס תשתמש ב output של ה templates הללו ותכיל אותם בתוך layout template (לא דיברנו עדיין ממש על הפרטים של ה view...) בשם invoice.html.erb (או invoice.xml.erb - אם מישהו משתמש עדיין ב XML/XHTML) שנמצא בתיקייה app/views/layout.
בגלל שריילס מודעת לקשרים בין הקבצים, היא תוסיף עבורנו, מאחורי הקלעים, את ה requires הנדרשים - כך שאין צורך לכתוב אותם.
אם יש לנו כמה controllers הקשורים זה לזה (למשל Admin screens), אנו יכולים להגדיר אותם בהיררכיה בתוך התיקיה app/controllers. אם הדפדפן ביקש URL בשל admin/user אז ריילס תחפש את ה controller בקובץ בשם user_controller.rb בתיקיה app/controllers/admin (כלומר: תת-התיקיה admin מקבצת את כל ה controllers בקבוצה).
בכדי למנוע התנגשות בין שני controllers בעלי אותו השם (נאמר user_conroller.rb בתיקיה app/controller/report), שם המחלקה יהיה namespaced ע"י מודול בשם של תת-התיקיה. במקרה שלנו: Admin::UserController.
רוצים לסדר את מבנה התיקיות בצורה שנוחה לכם? אולי ברור לכם עכשיו כמה קונפיגורציות תאלצו לנהל!
---
קישורים נוספים:
The Rails Doctrine - הרעיונות התכנוניים / פילוסופיים מאחורי ריילס.
מה ההבדל בין RDoc ל Markdown
?Is TDD Dead
A Conversation with Badri Janakiraman about Hexagonal Rails
פוסט על הארכיטקטורה של ריילס
[א] זו לא אמת חד-משמעית, אך כך מקובל להאמין.
[ב] Gems, הן ספריות קוד של רובי אותן ניתן להתקין בקלות (<gem install <gem name $) מ repository משותף-לכל. דומה ל npm packages של node.s, ל eggs של פייטון, או Pears (אגסים) של PHP.
[ד] יש כמובן את Scala, Elixier, Rust, ועוד. הצגתי את הבחירות הנפוצות של אנשי רובי.
[ה] טכנולוגיות אלו הן לא "של ריילס", אבל ריילס עושה בהן שימוש מקיף, ואלי גם השפיעה עליהן במידה:
[ו] Data Mapper, כמו Hibernate - מבודד את ה Domain מבסיס הנתונים, בכדי להפוך את ה Domain Logic לבלתי תלוי, קל לבדיקה (Unit Testing), ולאפשר שינויים בבסיס הנתונים במנותק מה Domain וליהפך. אמנם במקרים רבים הצוות משתמש ב Data Mapper כי זה "Best Practice" למרות שהכוונה הברורה היא שבסיס הנתונים יהיו מיפוי מדויק של המודל - או ליהפך (הכוונה: תמיד אובייקט = טבלה, בלי שום רמת הפשטה). כמובן שרמת ההפשטה האפשרית בפועל מעל בסיס הנתונים היא מסוימת - ולא "אינסופית". כדאי להזכיר ש Data Mappers נולדו בסביבת ה Enterprise, בה לעתים רבות לאפליקציה לא הייתה בלעדיות על ה Database schema.
ספציפית: אפליקציות עם ממשק וובי מצד אחד, ובסיס נתונים (בד"כ רלציוני, אבל לא רק) - בצד השני.
מדוע ריילס?
ריילס הגיעה כתגובה ל JEE (בימיו הפחות יפים - תחילת דרכו) וכאלטרנטיבה פשוטה ומהירה לכתיבת אפליקציות ווב. באותם הימים, מרכז הכובד של JEE היה ה Enterprise JavaBeans (בקיצור EJB) שהיו כבדים ומסובכים. למשל, ה Guideline היה לכתוב לכל רכיב שמייצג נתונים 4 Interfaces נפרדים (רגיל, Home, Remote, ו LocalHome - אם אני זוכר נכון). ל EJB היו ה-מ-ו-ן קובצי קונפיגורציה XML לא-ידידותיים, ולמרות הכל - זה היה טרנד חם ורבים עברו לעבוד בו.
JEE הביא יתרונות רבים (סביבת multi-platform סטנדרטית, המתאימה ל Enterprise), אך במחיר גבוה. הוא כנראה היה טוב יותר מ Microsoft DNA או CORBA (כנראה...), אבל היו אנשים שחשבו שאפשר להשיג את הערך בעלות נמוכה יותר.
אחד מהם הוא Rod Johnson שיצר את Spring Framework, ה Framework שהפך הכל להרבה יותר פשוט (בעיקר הציג אלטרנטיבה פשוטה ל EJBs) - ומה שאח"כ הפך להיות הסטנדרט של JEE, בצורת EJB גרסה 3.0 (שהעתיקה הכל, כמעט, מ Spring + Hibernate).
חלוץ אחר הוא David Heinemeier Hansson (ידוע גם בקיצור DHH), בחור דני צעיר יחסית (יליד 79) שעבד בחברה בשם 37singals (היום נקראת basecamp) שפיתחה לעצמה Framework יעיל מאוד לפיתוח מערכות ווב בשפת רובי. ה Framework הזה יצא כ Open Source ונקרא Ruby on Rails. נראה שריילס, אגב, השפיעה באזורים מסוימים גם על Spring בגרסאותיה המאוחרות (אני לא מדבר רק על Spring Boot) - ומשם היא השפיעה גם על JEE. בכלל, ריילס הוא Framework רק השפעה, שניתן למצוא השפעות שלו במקומות רבים בעולם התוכנה.
מקור השם Rails הוא כזה: "במקום להתקדם באיטיות, כל אחד במסלול שלו, הצטרפו אלי: אני קובע את הדרך - אבל תוכלו לנוע במהירות". ריילס הוא יישום של אוסף של best practices (ש DHH האמין שהן מוצלחות, לא אוסף גנרי) - שמתאימים זה לזה, ומסביבם נכתב Framework שהופך את השימוש בהם למאוד קל ומאוד מהיר. ריילס הוא לא סיפור על פלורליזם - זהו סיפור על דעה מוצקה כיצד נכון לפתח אפליקציות ווב. אם אתם רוצים להיות יעילים בריילס, עליכם לקבל עליכם את "The Rails Way", או לפחות את רובה. אם תקבלו - תגלו את אחד ה Framework הפרודקטייבים הקיימים לפיתוח אפליקציות ווב. ריילס פרחה ביוחד בסביבות של סאטראט-אפים, שהדבר שהכי חשוב להם הוא לספק Value מהיר לשוק שאותו הם עוד לומדים.
מקור השם Rails הוא כזה: "במקום להתקדם באיטיות, כל אחד במסלול שלו, הצטרפו אלי: אני קובע את הדרך - אבל תוכלו לנוע במהירות". ריילס הוא יישום של אוסף של best practices (ש DHH האמין שהן מוצלחות, לא אוסף גנרי) - שמתאימים זה לזה, ומסביבם נכתב Framework שהופך את השימוש בהם למאוד קל ומאוד מהיר. ריילס הוא לא סיפור על פלורליזם - זהו סיפור על דעה מוצקה כיצד נכון לפתח אפליקציות ווב. אם אתם רוצים להיות יעילים בריילס, עליכם לקבל עליכם את "The Rails Way", או לפחות את רובה. אם תקבלו - תגלו את אחד ה Framework הפרודקטייבים הקיימים לפיתוח אפליקציות ווב. ריילס פרחה ביוחד בסביבות של סאטראט-אפים, שהדבר שהכי חשוב להם הוא לספק Value מהיר לשוק שאותו הם עוד לומדים.
ריילס לא מושלמת - כמובן. ריילס פחות מתאימה למצבים בהם:
- תוכן האתר הוא סטטי / כל הדינאמיות היא בצד הלקוח.
- אפליקציות שאין להן בלעדיות על בסיס הנתונים (כלומר: הוא משותף עם עוד אפליקציות).
- אפליקציות שזקוקות לאינטגרציות רבות למערכות אחרת (בעיקר - כי זה עלול לשבור את ה flows שריילס הגדירה, ושקל לממש בעזרתה).
- אפליקציות עם scale גבוה, המורכבות מהרבה טרנזקציות קטנות (מכיוון שהתקורה שריילס מוסיפה על כל טרנזקציה היא משמעותית).
התכונות העיקריות של ריילס
ההחלטה התכנונית המרכזית של ריילס, אם כן, היא "פריון (productivity) על פני גמישות".
שני עקרונות מרכזיים שנוהגים להזכיר שוב ושוב, בהקשר של ריילס, הם:
- Convention over Configuration - במקום לומר היכן נמצא משהו (קובץ, משתנה, וכו') ומה שמו - בואו נגדיר כלל מוסכם (convention) היכן הוא אמור להימצא / איך הוא ייקרא - ונחסוך לנו את כל התקשורת הזו. הרעיון של CoC הוא לא חדש, ניתן למצוא אותו במייבן, למשל, שקצת קדמה לריילס. בכל זאת, ריילס היא זו שעשתה PR משמעותי מאוד לעקרון התכנוני הזה (ובמיוחד כ contra ל JEE) - והשפיעה בכך רבות על התעשייה.
- Don't Repeat Yourself (בקיצור DRY) - גם זה רעיון שכבר מקובל עשרות שנים, אבל ריילס חרטה אותו על דגלה. לא לכתוב בקוד שום דבר פעמיים.
בעזרת עקרונות אלו (ועוד כמה אחרים) הצליחה ריילס ליצור סביבה סופר-פרודקטיבית לכתיבת אפליקציות ווב. כלל אצבע אחד אומר שבריילס יהיה עליכם לכתוב חמישית משורות הקוד בג'אווה בכדי להשיג את אותה התוצאה.
ריילס צמחה על גבי שפת רובי, קצת רחוק מהקהילה הטבעית של ג'אווה (ה Enterprises), ולכן ההשפעה שלה הייתה קצת יותר רחוקה. אל דאגה! JEE ננגחה שוב ושוב על היתירות של הקוד שהיא יצרה (בתרגיל הנדסי כ"כ מרשים): גם ע"י NET. (מי שזוכר את קרבות ה PetShop) וגם ע"י Spring - בניצוחו של רוד ג'ונסון (Rod Johnson), שגילה מעט מאוד עדינות כלפי החבר'ה של JEE. היום מצבה של JEE טוב בהרבה מאשר היה באותם הימים, אבל עדיין - פיתוח בריילס נחשב מהיר בהרבה.
עוד אלמנטים מרכזיים בריילס שכדאי לציין הם:
הרחבה לשפת רובי:
רובי, כתכונה של השפה מאפשרת (ומעודדת) שימוש ב metaprogramming בכדי להרחיב את השפה עצמה וליצור DSLs חדשים. יכולות אלו, הן אולי הסיבה המרכזית שריילס הצליחה להיות יותר אפקטיבית [א] מספריות ווב אחריות (ASP.NET MVC, Lavarel או !Play) - שהיו משוחררות גם הן מ"כבלי ארכיטקטורת ה Enterprise של JEE". פקודות שימושיות בכתיבה של אפליקציות ריילס (למשל הגדרות שונות על המודל) הן בעצם הרחבות של ריילס לשפת רובי. מתכנת ריילס ללא רקע משמעותי ברובי עשוי לא להיות מסוגל להבחין אלו תכונות בהן הוא משתמש שייכות לשפת רובי - ואלו שייכות לריילס (ואולי גם לא ממש אכפת לו).
אינטגרציה:
ריילס כוללת stack של טכנולוגיות שמחוברות טוב מאוד זו לזו, ומספקות חווית פיתוח אחידה end-to-end. החל מבסיס הנתונים (Active Records - כלי ה ORM של ריילס), ועד צד הלקוח (SASS, Haml, ו CoffeeScript [ה]) - הכל מרגיש מתאים, ודומה למדי. החוויה דומה, אולי, לזו של פיתוח בפלטפורמת NET. של מייקרוסופט - לה שליטה רחבה על כל ה Stack הטכנולוגי.
עד גרסה 2, ריילס הייתה gem [ב] אחד, שלא גמיש להחלפות. החל מגרסה 2 חלק מהרכיבים (Active Records, למשל) הופיעו כרכיבים הניתנים להחלפה, אם כי ההחלפה בפועל הייתה מאתגרת למדי. ובמשך הזמן ממש התפתחו plug-in APIs המאפשרים לעשות החלפות אלו בצורה פשוטה יותר ויותר.
שלא תבינו לא נכון: אם אתם הולכים לכתוב אפליקציה ראשונה בריילס, ורוצים כבר בשלב זה להחליף רכיבים כראות עיניכם - זה לא ממש כדאי. החלפת רכיבים היא עדיין פרקטיקה מתקדמת שמומלצת רק למי שמבין היטב את דרכי העבודה של ריילס. באפליקציות הראשונות - כדאי להיצמד לסטדרטי ולמקובל.
הגישה שרואה בריילס "אוסף של רכיבים" (מה שטכנית באמת נכון) - מהם ניתן להרכיב תצורה מותאמת-אישית, נקראת (גם) Hexagonal Rails (ע"ש Hexagonal Architecture, שדוגלת בהפרדת ה domain model משאר הרכיבים, ורואה בהם סוג של plugins שמתחברים מסביב אליו) - והיא פחות נפוצה, ואולי אף שנויה במחלוקת: האם ההשקעה, הלא פשוטה, "לאלף את ריילס" מתירה בסופו של דבר תוצר שמצדיק את ההשקעה הזו?

ריילס כוללת stack של טכנולוגיות שמחוברות טוב מאוד זו לזו, ומספקות חווית פיתוח אחידה end-to-end. החל מבסיס הנתונים (Active Records - כלי ה ORM של ריילס), ועד צד הלקוח (SASS, Haml, ו CoffeeScript [ה]) - הכל מרגיש מתאים, ודומה למדי. החוויה דומה, אולי, לזו של פיתוח בפלטפורמת NET. של מייקרוסופט - לה שליטה רחבה על כל ה Stack הטכנולוגי.
שלא תבינו לא נכון: אם אתם הולכים לכתוב אפליקציה ראשונה בריילס, ורוצים כבר בשלב זה להחליף רכיבים כראות עיניכם - זה לא ממש כדאי. החלפת רכיבים היא עדיין פרקטיקה מתקדמת שמומלצת רק למי שמבין היטב את דרכי העבודה של ריילס. באפליקציות הראשונות - כדאי להיצמד לסטדרטי ולמקובל.
הגישה שרואה בריילס "אוסף של רכיבים" (מה שטכנית באמת נכון) - מהם ניתן להרכיב תצורה מותאמת-אישית, נקראת (גם) Hexagonal Rails (ע"ש Hexagonal Architecture, שדוגלת בהפרדת ה domain model משאר הרכיבים, ורואה בהם סוג של plugins שמתחברים מסביב אליו) - והיא פחות נפוצה, ואולי אף שנויה במחלוקת: האם ההשקעה, הלא פשוטה, "לאלף את ריילס" מתירה בסופו של דבר תוצר שמצדיק את ההשקעה הזו?
בדיקתיות:
תכונה אחרונה של ריילס שארצה לציין היא "בדיקתיות". יוצרי ריילס (ממש כמו יוצרי AngularJS, למשל) היו מודעים היטב לצורך בבדיקות - והם בנו תשתית שמאפשרת לבדוק את הקוד שרץ עליה בקלות יחסית. בדיקות יחידה ואינטגרציה הן חלק מובנה מריילס, ו flows הבדיקה מאופשרים היטב בכל הרמות , אם כי קצת יותר לכיוון ה integration tests וקצת פחות לכיוון ה isolated unit tests. כמות ספריות הבדיקה הזמינה לשפת רובי היא מרשימה (RSpec, MiniTest, Test::Unit, Cucumber, Factory_girl), ולכמה מהספריות הללו יש הרחבות מיוחדות לריילס (למשל Rspec_rails או Factory_girl_rails). בדיקות הוא לא רעיון זר בקהילת הרובי או ה RoR...
מעניין לציין שדווקא DHH הוא זה בשנה האחרונה העלה כמה דברי ביקורת על כתיבת בדיקות. בגלל ש DHH קידם מאוד את תרבות כתיבת הבדיקות (וגם בגלל שהוא הגורו הבלתי-מערוער בעולם של ריילס?) - דבריו זכו לתהודה רבה. הוא כתיב פוסט בשם Test-induced design damage, ואח"כ העביר סשן בשם "?Is TDD Dead". בסוף הפוסט תוכלו למצוא לינק לסדרת הסשנים המעניינת בה הפגישו אותו עם יוצר ה TDD (קנט בק) ומרטין פאוולר (ששימש כמגשר?). סדרה של 3 שעות - אך בהחלט מעניינת.
כחובב Testing מושבע, ואני מדגיש - מושבע, אני חושב שדיוויד עלה פה על רעיון שבעיקרו הוא נכון - אך זקוק לעוד ליטוש וזיקוק. כבר הספקתי לשמוע כמה קולות שהשתיקו אותו כ"לא רציני", או כ "סתם" - אבל דווקא זה אחד הנושאים, המוצדקים בעיני ,שהוא מעלה: שמי שעושה Testing עושה זאת לעתים קרובות מדי מתוך "אמונה" ולא מתוך "הוכחת תועלת ברורה". הוא לא טוען ש Testing הוא פרקטיקה לא טובה או שיש להימנע ממנה - אבל הוא מציע (בצורה לא כ"כ מפורשת) לשנות אותה, ולצמצם אותה במקומות מסוימים.
ריילס בחזית הטכנולוגיה
ריילס בחזית הטכנולוגיה
בעולם של Single Page Applications, בעולם בו חווית משתמש שהפכה מקובלת, שדורשת שקוד משמעותי ירוץ בדפדפן, ובעולם של noSQL - ריילס כבר זוהרת פחות. אפשר לעשות את כל הדברים האלו עם ריילס, אבל היא כבר לא יעילה כמו שהייתה בעבר, ומפתחי ריילס צריכים לפעמים להיות יבשושים ולכתוב קוד משעמם / קצת פחות יעיל.
אם אתם מחפשים את החלופה "העכשווית" לריילס שתוכננה במקור לקוד צד-לקוח משמעותי, ו MongoDB - אתם כנראה מחפשים את MeteorJS (עם כל היתרונות, וגם החסרונות שלה).
אכן נראה שחלק ממפתחי הריילס (כלומר: רובי + ריילס) עוזבים את ריילס ומחפשים Frameworks חדשים לעבוד איתם. הטיעון ששמעתי כבר כמה פעמים הוא "אני לא רואה הגיון לעשות MVC גם בשרת וגם בצד הלקוח" (ברור שלא! מוזר לשמוע בכלל ניסו כזה דבר). באופן טבעי, חלקם מחפשים את המוכר, ולא מפתיע למוצא frameworks שמנסים לספק את הצורך הזה. קשה לי שלא לציין את Sails - של node.js ו grails של שפת גרובי (groovy). האחרון הוא לא חדש - אבל קשה להתעלם מהצליל המוכר שהוא בחר לעצמו :)
הרכיבים העיקריים בריילס
ריילס בבסיסה היא ספריית MVC שמושפעת ישירות מה MVC (המקורי) של שפת smalltalk:
המודל - שומר את ה state של המערכת (בעזרת בסיס הנתונים, אם כי לפעמים רק בזכרון), אוכף "חוקים עסקיים" על נכונות ה data (למשל: סטודנט חייב להיות רשום לתוכנית לימודים כלשהי). הוא לא בהכרח המאמת היחידי של הנתונים, אלא ה gatekeeper לפני שהמידע נשמר / משותף עם חלקים אחרים במערכת. בניגוד ל MVC של Smalltalk הוא גם כולל חלק מהלוגיקה - ראו בהמשך את ההסבר על Active Records.
המודל, בגדול - הוא זמין לכלל האפליקציה, אין בו partitioning (או bounded context).
ה View - הוא הקוד שמייצר דפי HTML למשתמש, על בסיס מידע במודל. ריילס היא תשתית לכתיבת MVC בצד-השרת (כלומר: השרת מייצר HTML, ומוסיף JavaScript לאינטרקטיביות). בדומה למודל ה MVC הקלאסי ה View לא מקבל input מהמשתמש, ולא מנהל איתו שום סוג של אינטרקציה (לפחות לא בצד-השרת).
ה controller - אחראי לקבלת קלט מהמשתמש, טיפול בו, ותפעול (ניתן לומר: orchestration) של המערכת עד שהמשתמש מקבל בחזרה את התשובה שלו. דרך העבודה שלו היא לעדכן את המודל, ואז להזניק את ה View המתאים (הוא לא מעביר מידע ל view ישירות).
בריילס יש גם routers - שהם ממפים URLs, ומצבים - ל Views. לדוגמה: אם משתמש שהוא admin ניגש לדף מסוים - הוא יקבל View אחר ממשתמש רגיל. ה router עושה מה שבמערכות אחרות עושה סוג של "super controller". הוא דקלרטיבי, בעזרת סט של ״פקודות״ מיוחדות לעניין (מה שהופך אותו לפשוט יותר לכתיבה ותחזוקה) - וסה"כ הוא מהווה הרחבה מבורכת על מודל ה MVC ה"קלאסי".

Active Records (בקיצור: AR)
כלי ה lightweight ORM של רובי, המנהל בפועל את הגישה לבסיס הנתונים של המודל. רובי מספקת גם כלים להגדרת טבלאות ברובי דקלרטיבי (ולא SQL, על הווריאנטים תלויי בסיס הנתונים הספציפי שלו) וכלים מובנים לביצוע migrations בין גרסאות שונות לסכמת בסיס הנתונים (מה שמקובל בג׳אווה לעשות עם flyway).
השם "Active Records" הוא בעצם של שם של דפוס-עיצוב (מופיע בספר PoEAA) אותו המודול מממש.
דפוס העיצוב "Active Record" מגדיר מחלקה בשפה (במקרה שלנו: רובי) שמתארת נתונים של שורה (להלן Record) בבסיס הנתונים, אבל מוסיפה עליהם גם את התנהגות ה domain הרלוונטית לאותם נתונים (להלן Active). למשל: validation, חישובים, derived fields, וכו'. הבהרה: יש מחלקה אחת לכל טבלה, ומייצרים מופעים שלה ע"פ הרשומות להם נזקקים באותו הרגע.
דפוס עיצוב זה מרשה לערבב בין מיפוי הנתונים בין בסיס הנתונים לזיכרון, עם לוגיקה עסקית - כל עוד הלוגיקה העסקית היא רק ברמה של הרשומה הבודדת (ולא "שייכת" ל scope רחב יותר). ערבוב זה, נמצא בוויכוח תמידי על הלגיטימיות שלו, מכיוון שהוא סותר כלל מקובל בארכיטקטורה הנפוצה ביותר למערכות מבוססות-נתונים (הרי היא Layered Architecture) - הפרדה בין Persistence ל Business Logic, או בצורת דפוס העיצוב "Data Mapper" אותה מממשים רוב כלי ה ORM המוכרים - הפרדה מוחלטת בין לוגיקה עסקית למיפוי הנתונים בין בסיס הנתונים לזיכרון [ו].
בריילס, יידרש מאמץ מיוחד בכדי לא-לעבוד עם Active Records, אז כדאי שתתנו לדפוס זה הזדמנות - גם אם כל חייכם "גדלתם" על Data Mappers ;-).
Active Records מאפשר לנו לכתוב אובייקט "פשוט" ברובי, לרשת מ ActiveRecord::Base ולקבל את פעולות ה CRUD הבסיסיות ע"י סיפוק הגדרות בסיסיות של מה שאנו רוצים (declarative programming).
לא! זה לא "בחינם", אין ארוחות-חינם בהנדסת תוכנה. אנו מוותרים על גמישות וקצת על ביצועים - בכדי לקבל את הנוחות הזו.
Active Records מכתיב כללים מוסכמים לשמות - בכדי לצמצם את הצורך בהגדרות דומות, בכל פעם מחדש.
למשל: שם הטבלה בבסיס הנתונים צריך להתאים לשם המחלקה (בוריאציה מסוימת), וכן שמות ה primary key וה foreign_keys, ועוד. פרטים על כללי השמות - אספק בהמשך הפוסט. אפשר שתהיה חוסר התאמה בשמות - אבל אז צריך לכתוב קונפיגורציה לכך.
את שאר הרכיבים אזכיר בקצרה, לא כי הם פחות חשובים, אלא בגלל שנדרש ידע נוסף בריילס על מנת להבין אותם.
- Action Pack - זהו הרכיב שמתפעל את ה MVC בריילס. כל פעולת משתמש בריילס נקראת "Action". הוא מורכב מ -3 תתי-מודולים:
- Action Dispatch - אחראי ל routing.
- Action Controller - מספק את מחלקת ה ActionController::Base ממנה יורשים כל ה controllers במערכת.
- Action View - אחראי לרינדור ה Views, בעזרת מנגנון ה ERB (קיצור של Embedded Ruby) - מנגנון שדומה מאוד ל JSP בג'אווה או ל PHP: סוג של template (בד"כ HTML, יכול להיות אחר) שבו מושתל קוד רובי המתאר את ההתנהגות הדינאמית.
- Active Model - המשמש כ Facade של AR מול ה Action Pack.
- Active Resource - המספק יכולות צריכה של שירותי REST חיצוניים. סוג של שירות אינטגרציה בין מערכות.
- Active support - סט של utilities כלליים (שימושיים) שמגיע עם ריילס. המקבילה של Apache Commons - של מג'אווה.
- Action Mailer - אשר תופס בתיעוד, משום מה, נתח מכובד. הוא בסה״כ שולח מיילים.
- Active Job - לניהול Queues של jobs. הוא בעצם שכבת הפשטה למימושים קיימים (כגון Resque) ולא מימוש בפני עצמו. הוא חדש בריילס 4.2 .
- Railties ("קשרי מסילה") - זהו ה gluing logic של כל רכיבי ה Active / Action למיניהם. ה Strategy של תפעול אפליקציות הריילס.
- Rails - רכיב קטן למדי, שאחראי על אתחול המערכת - והכנסת המודולים האחרים לפעולה.
כל עבודת ה low-level ברמת ה HTTP הוא לא חלק מריילס. חלק זה יטופל ברמת ה Application Server - עליו נדבר בהמשך.
מבנה אפליקציית ריילס
כחלק מה Convention over Configuration, לאפליקציית ריילס יש מבנה תיקיות מוסכם-מראש. בכדי ליצור מבנה זה יש להקליד בשורת הפקודה:
$ rails new <app name> [optional: -d < sqlite3 | mysql | postgresql >]
d- הוא פרמטר שמגדיר באיזה בסיס נתונים אתם הולכים להשתמש - והוא יחסוך לכם יצירה של כמה קונפיגוריות בצורה ידנית מאוחר יותר.
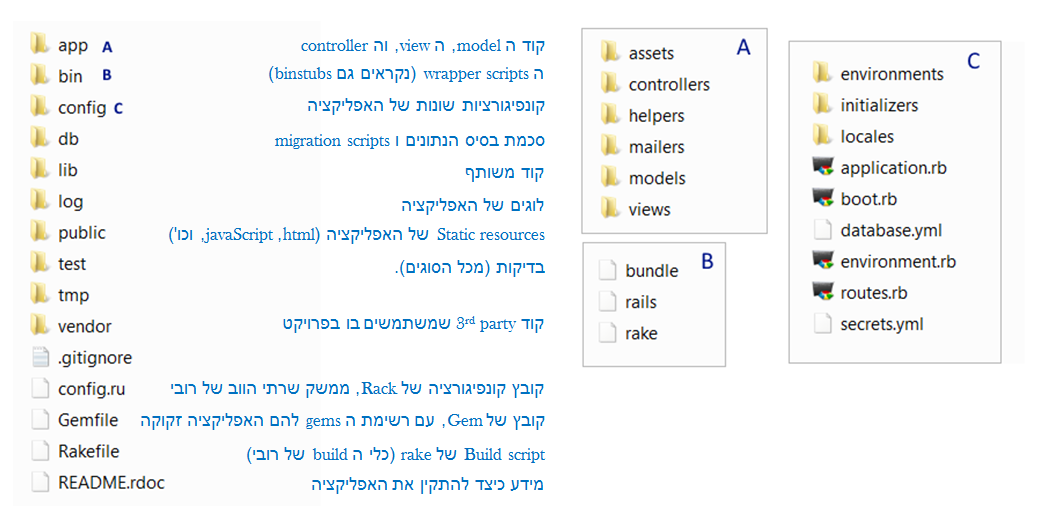 |
| מבנה אפליקציית ריילס חדשה |
התיקיות המעניינות ביותר באפליקציית הריילס הן תיקיות ה app, config, ו lib. אם יש בדיקות טובות - הוסיפו לכך (במקום גבוה) את תיקיית ה tests (לפעמים תראו אותה בשם spec).
תיקיית ה bin כוללת את הסקריפטים לפעולות הבסיסיות של האפליקציה. אלו בעצם wrapper scripts (נקראים ברובי גם binstubs) שרק מכינים את סביבת הריצה ואז קוראים ל executable הנכון. לפני ריילס גרסה 4 קראו לתיקיה זו בשם "scripts".
קובץ ה Gemfile (מתחיל באות גדולה) הוא קובץ של כלי רובי בשם bundler, כלי שעוזר להגדיר, ואז להתקין - תלויות (gems [ב]) על סביבות חדשות בהן תרוץ האפליקציה.
ברגע שמריצים את הפקודה "bundle install", אז bundler יקרא את קובץ ה Gemfile, יבדוק מהן הספריות הנדרשות וגרסאותיהן, ויתקין את מה שלא נמצא - בגרסאות המתאימות. אם אתם מכירים את קובץ ה package.json של node.js - זה ממש אותו הדבר.
קובץ ה Gemfile שנוצר בעקבות הפקודה "rails new" כולל כבר רשימה של ספריות שימושיות: דרייבר לבסיס הנתונים שהגדרתם, כמה ספריות צד-לקוח, ספרייה ל generation של תיעוד, ספריה לעבודה עם JSON, וכו'.
Gemfile.lock הוא קובץ בו bundler מנהל לעצמו את הגרסאות שמותקנות בפועל. זהו קובץ שתרצו להכניס ל git repository שלכם - אך לא לשנות ידנית (אין קשר לקבצי lock של MS Office, שמטפלים ב concurrency).
קובץ ה rakefile הוא של כלי ה build של רובי שנקרא rake. ה build ברובי כולל בעיקר בדיקות, פענוח הסכמה, Linting, וטיפול בקצבי HTML ו CSS (למשל: minification).
קובץ ה rakefile של ריילס יהיה לרוב מינימלי, והדבר המרכזי שהוא יעשה הוא לטעון ולהריץ רשימה של rake tasks (שאתם תכתבו). קבצי ה task יושבים בתיקיה lib/tasks.
בריילס, עובדים לא מעט עם command line עבור scaffolding [ג]: ניהול בסיס הנתונים, ביצוע buid, הרצת האפליקציה, ועוד.
לפעמים הפקודות הללו לא עובדות כראוי, ו"טריק" מקובל הוא לקרוא ל <bundle exec rake <rake params - מה שהופך את כל ה gems שמצוינים ב Gemfile לזמינים, אפילו אם הם לא ב path של מערכת ההפעלה.
התיקייה lib, ע"פ הגדרה אחת, כוללת קוד שהוא לא מודל, controller, router, או View.
התיקייה lib, ע"פ הגדרה נוספת, כוללת קוד שניתן לעשות שימוש חוזר בו בין הרכיבים השונים (view, model, controller).
מלבד כמה תתי ספריות נדרשות (למשל tasks) - יש לכם חופש כיצד לארגן אותה.
בגרסאות ישנות של ריילס, כל הקבצים שישבו ב lib נטענו כזמינים לכל הרכיבים במערכת. כלל זה שונה והיום עליכם להדיר במפורש באיזה lib רכיב ה app שלכם רצה להשתמש - בכדי להשתמש בו. ( או פשוט להוסיף ל config/application.rb את הפקודה config.autoload_paths += %W(#{Rails.root}/lib שתעשה מה שריילס עשתה בגרסאות ישנות).
נוהגים לומר שהקהילה של ריילס "התבגרה" בשנים האחרונות. ריילס "ניסתה לדלג" על כל מיני כללים מקובלים של הנדסת תוכנה בכדי להאיץ את קצב הפיתוח. חלק מהדילוגים הללו הוכחו כבעייתיים - ואז ריילס חזרה בה (נראה לי שהמקרה הנ״ל הוא אחד כזה). דילוגים אחרים - אולי הוכחו כלא בעייתיים, בהקשרים בהם ריילס עובדת. אני זוכר ששמעתי דיונים על כך בקהילת הג'אווה לפני מספר שנים: "הנה ריילס מתבגרת, והחברה שם עושים היום יותר ויותר הנדסת תוכנה כמו ג'אווה". המסקנה שהוסקה (שגם לי נראתה הגיונית, בזמנו) הייתה ש"ג'אווה צדקה" (שהחילה על עצמה כל כלל אפשרי של הנדסת תוכנה) - וריילס "בדרך להיות סוג של ג'אווה".
נו טוב, סתם רכילות cross-קהילתית.
שני קבצים חשובים שנטענים בעליה של ריילס הם config/environement.rb ו config/application.rb.
בנוסף תמצאו בתיקיה config/environemnts קובץ קונפיגורציה לכל סוג סביבה: development, production ו test - זה הבסיס למערכת ה staging של ריילס.
כשמפעילים את אפליקציית הריילס, ניתן לציין את הסביבה כפרמטר, למשל:
$ rails server - e development
בכדי לטעון קונפיגורציה לסביבת ה staging המתאימה.
זהו.
ייתכן ותתקלו בקבצים ריקים בשם ״keep.״. מטרתם היא למנוע מכלים מסוימים להתעלם מהתיקיות שנוצרו ע"י "rails new" - וניתן (ומומלץ) למחוק אותם כאשר התיקיה מתמלאה בתוכן. חבל לראות פרויקט ריילס בן כמה שנים - שעדיין שמר את הקבצים הללו.
 |
| החידושים שהגיעו עם ריילס 4, ששוחררה באמצע 2013. גרסה מג'ורית של ריילס משוחררת אחת לשלוש שנים, בערך. מקור. |
ה Application Server
הפעלת האפליקציה נעשית ע"י פקודת "rails server", או בקיצור "rails s".
כל אפליקציית ריילס רצה על "שרת ווב משלה", בתוך תהליך של מערכת ההפעלה. ניהול של כמה אפליקציות על אותו שרת פיסי, מתרחשת ע"י הפעלה של כמה "תהליכי שרת", אולי מסוגים שונים ו/או גרסאות שונות.
ריילס מגיע כברירת מחדל עם שרת "רזה" בשם WEBrick. זהו שרת פשוט למדי - שמשמש בעיקר לצורכי פיתוח (ולא ל production). ב Production מקובל להשתמש ב Puma, Raptor או ב Unicorn.
Rack הוא שמה של הספציפיקציה של שרת ווב ברובי, וגם השם של ה Reference Implementation שלה.
Rack דומה בתפקידו ל Servlet API של ג'אווה, שבמקרה יש לו גם מימוש באותו השם (דמיינו ש Tomcat נקרא "Servlet"). החלק החשוב יותר של Rack הוא הספסיפיקציה. כנראה שהחבר'ה של רובי ראו מה קרה בעולם של פייטון, שבו לא היה תקן שכזה, וכל שרת ווב עושה את אותו הדבר - אבל מגדיר זאת אחרת.
סה"כ ה API ש Rack מציע הוא מאוד בסיסי: הוא עובד ברמת הפשטה מאוד נמוכה - ה HTTP Request-Response Lifecycle (בדומה ל CGI - אם אתם ותיקים מספיק בכדי לדעת מה זה).
מצד מימושי השרת, המימושים הנפוצים ביותר הם Rack (כמובן), Unicorn, או Mongrel.
ספסיפקציית ה Rack משתמש לא רק את RoR, אלא גם Frameworks אחרים כגון Sinatra, Ramaze ו Merb (שמוזג לתוך RoR בגרסה 3.0).
כמה מלים על Rack כ reference implementation:
מקור השם Rack הוא הכוננית בחדר השרתים שעליה מתקינים את השרתים / ציוד הרשת. יוצריו בחרו בשם זה בגלל מנגנון ה plugins שלו, שמאפשר למודולים צד שלישי (הנקראים middleware, דומים ל Servlet Filters בג'אווה) להרחיב אותו בקלות. הנה רשימה של מודולים זמינים.
מעניין להזכיר את Rack::MockRequest שמייצר mocks לאובייקטי request ו response (נחמד שזה מגיע מ"הספק"), ו Rack::Lint שעושה Linting על קוד המשתמש ב API של Rack ומוצא כמה common pitfalls.
קובץ הקונפיגורציה של Rack, הנקרא config.ru מכיל את ההגדרה של ה middlewares שאנו משתמשים בהם, ו metals.
Rails Metal Apps (בקיצור: metal, מלשון "bare-metal" - אני מניח) הן חתיכות קוד באפליקציית הריילס שלנו, שירוצו ישירות מעל ה API של Rack, ללא תוספות.
מדוע לעשות זאת? בגלל ביצועים, למשל: כדי לספק REST API שקוראים לו בקצב מהיר.
ה stack של ריילס שמריץ את ה controllers (ה Action Controller Stack) מציב תקורה משמעותית לכל request שמטופל. אם אנו רוצים לספק תשובה פשוטה, ולעשות זאת מהר - כדאי לעקוף אותו.
הערה: ברור שאם אנו זקוקים לביצועים ממש גבוהים - גם metal עדיין מציב מגבלה על מה שאפשר להשיג מהחומרה. שפת רובי היא לא concurrent (השתפרה, אבל עדיין לא ממש) ואין לה parallelism. כדי להגיע ל throughput או tps גבוה במיוחד - כדאי לשקול עבודה נקודתית עם node.js (עבור קוד "רעב" ל I/O) או עבודה ב Go (עבור קוד "רעב" ל CPU) [ד].
אחרונה חביבה, היא ספרייה בשם spring שעובדת עם rake (שהיא כבר חלק מובנה מריילס 4.1 ומעלה) שעושה preloading לשינויים באפליקציית הריילס מבלי לעשות restart לשרת (אלא על בסיס של fork של ה process - לא עובד ב Windows או ב JRuby). יכולת דומה קיימת באופן מובנה בשרת ה Unicorn.
ה Conventions של ריילס
כפי שהזכרנו כבר קודם לכן, ריילס מציגה כללי naming שאם תעבדו לפיהם - תצטמצם מאוד כמות הקונפיגורציה שתצטרכו לנהל. בפועל - דרך העבודה המקובלת בריילס היא להצמד באופן מוחלט ל conventions, בכדי להימנע מניהול קונפיגורציות עד כמה שניתן.
בכדי להבין את ה conventions, אזכיר שאנו נמצאים ברובי - ולכן על ריילס היה להתאים את עצמה גם ל conventions של רובי (אותם סקרתי בפוסט שפת Ruby - מה זה השטויות האלה?!).
שמות של טבלאות בבסיס הנתונים יהיו ב snake_case - כמו משתנים. טבלאות תמיד יקראו ע"פ צורת הרבים של האובייקט (plural): למשל People או Invoices ולא Person או Invoice.
למה? כדי שהקוד יהיה קרוב יותר לשפה הטבעית: "Select a Product from products". אני מניח שהבדל זה יכול גם להקל להבחין מהר בין מחלקה לטבלה בבסיס הנתונים.
שמות של קבצים (model, view, controller, וכו') יהיו גם הם ב snake_case - כפי שמקובל ברובי גם מחוץ לריילס.
נניח שאנו רוצים ליצור מודל בשם LineItem (שם מחלקה ברובי הוא CamelCase). כדי שהכל יעבוד, ללא קונפיגורציה נוספת, על שם הקובץ המכיל את המחלקה להיות line_item.rb (והיא תהיה בתיקייה app/models), ועל שם הטבלה בבסיס הנתונים להיות line_items.
"אני מבין איך עושים זאת עבור line_items, אבל איך *לעזאזל* ריילס תקשר עבורי בין people ל person?". שאלה טובה. הציצו ב utility של ActiveSupport שעושה זאת: inflections.rb. הוא מכיר יוצאי-דופן מוכרים כמו person-people או octopus-octupi, ואתם גם יכולים ללמד אותו כללים חדשים, למשל: selfie-selfieez.
ל controllers יש כללים נוספים:
אם יש לנו Controller ששם המחלקה שלו הוא InvoiceController, אז עליו להיות בקובץ בשם invoice_controller.rb שנמצא בתיקייה app/controllers. עד כאן - זה כמו המודלים.
בנוסף, ריילס תצפה שיהיה קובץ נוסף בשם invoice_helper.rb בתיקייה app/helpers שיכיל מחלקה בשם InvoiceHelper.
ריילס גם תצפה שה view templates של ה controller הזה יהיו בתיקיה בשם apps/views/invoice. כהתנהגות ברירת מחדל, ריילס תשתמש ב output של ה templates הללו ותכיל אותם בתוך layout template (לא דיברנו עדיין ממש על הפרטים של ה view...) בשם invoice.html.erb (או invoice.xml.erb - אם מישהו משתמש עדיין ב XML/XHTML) שנמצא בתיקייה app/views/layout.
בגלל שריילס מודעת לקשרים בין הקבצים, היא תוסיף עבורנו, מאחורי הקלעים, את ה requires הנדרשים - כך שאין צורך לכתוב אותם.
אם יש לנו כמה controllers הקשורים זה לזה (למשל Admin screens), אנו יכולים להגדיר אותם בהיררכיה בתוך התיקיה app/controllers. אם הדפדפן ביקש URL בשל admin/user אז ריילס תחפש את ה controller בקובץ בשם user_controller.rb בתיקיה app/controllers/admin (כלומר: תת-התיקיה admin מקבצת את כל ה controllers בקבוצה).
בכדי למנוע התנגשות בין שני controllers בעלי אותו השם (נאמר user_conroller.rb בתיקיה app/controller/report), שם המחלקה יהיה namespaced ע"י מודול בשם של תת-התיקיה. במקרה שלנו: Admin::UserController.
רוצים לסדר את מבנה התיקיות בצורה שנוחה לכם? אולי ברור לכם עכשיו כמה קונפיגורציות תאלצו לנהל!
---
קישורים נוספים:
The Rails Doctrine - הרעיונות התכנוניים / פילוסופיים מאחורי ריילס.
מה ההבדל בין RDoc ל Markdown
?Is TDD Dead
A Conversation with Badri Janakiraman about Hexagonal Rails
פוסט על הארכיטקטורה של ריילס
---
[א] זו לא אמת חד-משמעית, אך כך מקובל להאמין.
[ב] Gems, הן ספריות קוד של רובי אותן ניתן להתקין בקלות (<gem install <gem name $) מ repository משותף-לכל. דומה ל npm packages של node.s, ל eggs של פייטון, או Pears (אגסים) של PHP.
[ג] פירוש המילה: פיגומים. הוספת templates קטנים (controller חדש, מודל חדש) תוך כדי עבודה ע"י הפעלה ב command line של "... rails generate", או בקיצור: "... rails g". זו המקבילה הרזה ל Create New <...> Wizard ב Eclipse, למשל. פקודת rails generate דומה מאוד ל Yo - למי שמכיר, ובעצם הייתה עבורה מקור ההשראה.
[ד] יש כמובן את Scala, Elixier, Rust, ועוד. הצגתי את הבחירות הנפוצות של אנשי רובי.
[ה] טכנולוגיות אלו הן לא "של ריילס", אבל ריילס עושה בהן שימוש מקיף, ואלי גם השפיעה עליהן במידה:
- SASS - שפת מטא ל CSS
- Haml - תחביר מקוצר ל HTML
- CoffeeScript - שפת מטא לכתיבת ג'אווהסקריפט, בתחביר שדומה לשפת רובי.
[ו] Data Mapper, כמו Hibernate - מבודד את ה Domain מבסיס הנתונים, בכדי להפוך את ה Domain Logic לבלתי תלוי, קל לבדיקה (Unit Testing), ולאפשר שינויים בבסיס הנתונים במנותק מה Domain וליהפך. אמנם במקרים רבים הצוות משתמש ב Data Mapper כי זה "Best Practice" למרות שהכוונה הברורה היא שבסיס הנתונים יהיו מיפוי מדויק של המודל - או ליהפך (הכוונה: תמיד אובייקט = טבלה, בלי שום רמת הפשטה). כמובן שרמת ההפשטה האפשרית בפועל מעל בסיס הנתונים היא מסוימת - ולא "אינסופית". כדאי להזכיר ש Data Mappers נולדו בסביבת ה Enterprise, בה לעתים רבות לאפליקציה לא הייתה בלעדיות על ה Database schema.