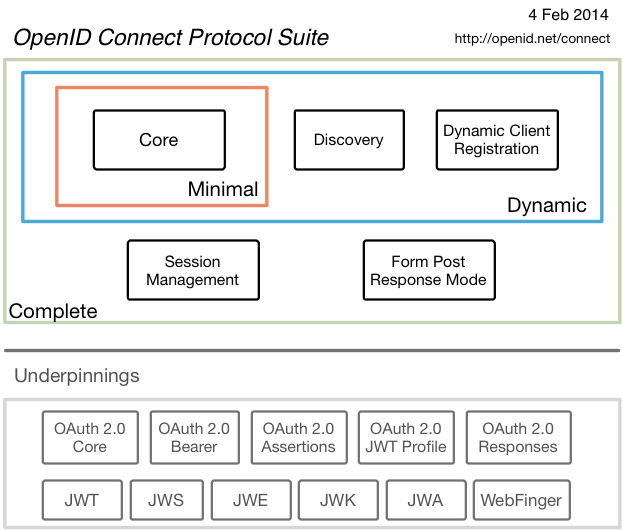
אחד הכנסים האהובים עלי, שאני נוהג לעקוב אחרי התוכן שמוצג בו הוא כנס ;goto
ה Keynote ב Goto Chicago שהתקיים לפני מספר ימים היה של מרטין פאוולר, בו הוא ביצע סיווג של סגנונות של "Event-Driven Architecture" (או בקיצור: EDA).

יש לי באופן אישי בעיה עם ההגדרה "Event-Driven Architecture".
לומר ש "יש לנו ארכיטקטורה שהיא Event-Driven" זה כמעט כמו לומר "יש לנו ארכיטקטורה שהיא Database Driven" או "ארכיטקטורה שהיא Java Driven". כלומר:
א. אנחנו מציינים כלי - ולא פרט מרכזי על מבנה המערכת.
ב. באמת, שלא ניתן ללמוד שום-דבר מהאמירה הזו.
בכלל, ככל שמערכת גדלה, ובמיוחד כאשר היא נעשית מבוזרת - יותר סביר שנשתמש באירועים איפשהו במערכת. האם זה הופך את המערכת שלנו ל Event-Driven?
ובכן... מדוע אנשים מציינים שיש להם "Event Driven Architecture"? כנראה כי:
א. זה נשמע "טוב". באזז מרשים.
ב. כי אותם אנשים מרוצים מהשימוש ב events - ונתונים לתכונה הזו של המערכת דגש מיוחד.
ראיתי מערכת או שתיים בחיים, שבאמת לא הייתה בהן כמעט תקשורת סינכרונית, וכמעט הכל טופל ב events. המודל הזה יכול להיות יעיל מאוד ל load גבוה, כאשר יש שורה של שלבים בעיבוד נתונים.
הייתי קורא למערכת כזו "Event Based", ומנסה להבין מה מניע את המערכת והארכיטקטורה שלה. האם מדובר ב Scalability? האם חלוקה של תהליך עיבוד ליחידות קטנות ופשוטות יותר?


זה המקרה הפשוט בו אני רוצה להעביר הודעה בין מודול א' למודול ב' בצורה אסינכרונית.


מה קורה כאשר מידע נוסף נמצא על מערכת שלישית? למשל, את הפרט אם נסיעה התחילה בשדה תעופה (ואז יש לתת 30% הנחה ;-)) ניתן להסיק רק כאשר יש נתונים נוספים ממערכת האזורים?
גם כאן יש בחירה: אפשר לתת את המשימה למערכת ששולחת את ה event, או לזו שמקבלת אותו. כנראה הבחירה תעשה ע"פ איזו תלות בין המערכות - היא סבירה יותר.

Event Sourcing
הרעיון בגישה זו היא שאנו שולחים אירועים על שינוי state של האובייקט, אבל ה event מכיל רק את השינוי הספציפי - ה delta. אנחנו גם מאחסנים את הנתונים בצורה הזו.
לצורך העניין אין מחיקות או דריסות של שדות - רק שורה של שינויים באובייקט.

אם מישהו רוצה לקרוא את האובייקט - הוא צריך להרכיב את שרשרת השינויים בכדי לקבל את האובייקט העדכני.
מה התועלת בגישה הזו?
פה עשויה לעלות שאלה פילוסופית: אם אני מקבל את העדכונים כ delta, אבל אז בכל עדכון עושה merge עם האובייקט שאני מחזיק אצלי - האם זה עדיין Event Sourcing?
אפשר לומר שכן - ההצהרה הזו עדיין תעזור לאנשים לקבל במשפט אחד תובנה על המערכת. מניעת racing condition הוא ערך גדול בפני עצמו. יש פה tradeoff כמובן: ביטול חסרונות משמעותיים - מול איבוד כמה מהיתרונות האחרים. זהו tradeoff סביר לחלוטין.
Command Query Responsibility Segregation (בקיצור: CQRS)
מספרים שאם הייתם מחפשים בגוגל "CQRS" לפני עשור, הוא היה שואל: "`?did you mean `Cars"
הרעיון הוא דיי ישן, ומקורו בשנות השמונים, אבל רק בשנים האחרונות הוא הפך למאוד-מוכר.
אני מניח שהרוב הגדול של הקוראים מכיר את השם, אבל לא בהכרח מכיר את הרעיון מאחוריו. לרוב האנשים CQRS מתקשר ל "high performance".
האמת שהרעיון של CQRS אינו קשור קשר ישיר ל events, אבל פעמים רבות - משתמשים בו כך.
הרעיון בגדול אומר:
קיים מודל אחד לכתיבה של אובייקט, ומודל נפרד לקריאה של אובייקט.

מתי זה שימושי?
כאשר דפוס הקריאה ודפוס הכתיבה שונים זה מזה.
למשל: נניח בטוויטר (אני מספר מהזיכרון - ייתכן שזה לא מה שקורה שם) כתיבה של טוויט (להלן: Command) הולכת למודל הכתיבה. שחררתי את הטוויט מהר והמשכתי לאינסטגרם.
כאשר משתמש אחר נכנס לטוויטר, הוא רוצה לראות את הפיד של הטוויטים מיד. אם נתחיל לעשות Query אחר כל האנשים שהוא עוקב אחריהם, וכל הטוויטים שלהם, ואז נמיין אותם ע"פ הסדר -זה ייקח הרבה זמן! יותר מדי.
במקום זה, לאחר שכתבתי את ה tweet יש Background Processor שמעתיק את הטוויט שלי לפיד של כל העוקבים.
כלומר:
שימוש אחר של CQRS הוא לא דווקא מבחינת ביצועים גבוהים, אלא פשטות של הקוד. אם המודלים סבוכים למדי - החלוקה ל"מודל כתיבה" ו"מודל קריאה" יקטינו את ה code base בחצי, בערך.
כאן שווה לציין ש Event Sourcing ו CQRS הולכים יד ביד זה עם זה:
מודל הכתיבה הוא ה State Log - אבל יש מודל קריאה שהוא המצב העדכני. זה יכול להיות בסיס נתונים או טבלה אחרת בה שומרים את המצב העדכני, וזה יכול להיות מודל שעובד מעל אותם נתונים - ורק מכיל את הקוד של "השטחת" העדכונים בזמן ה Query.
התלהבתי מהסדר שפאוולר עשה בנושא ה Event-Driven, ולכן כתבתי את הפוסט והוספתי עוד כמה תובנות משלי.
השארתי קצת אפור בהגדרות של הגישות השונות. תמיד ניתן לערבב ולייצר וריאציות. למשל:
הייתי מעורב בבניית מערכת שמבצעים בה רפליקציה של נתונים לשירותים אחרים, כמו בגישת ה Event-Carried State Transfer - בכדי להשיג High Availability. מצד שני, כמות הנתונים שמועתקת היא קטנה ומדודה מאוד, והנתונים הם ברמת הפשטה של ממשק ולא מבנה נתונים פנימי - כך שאין פגיעה בהכמסה של המערכת.
אם הייתי מנסה לתעד כל וריאציה שימושית בפני עצמה - כנראה שהיינו גומרים עם 16 צורות לשימוש ב Events ולא ארבעה, מה שהיה מאריך את הפוסט אבל יותר גרוע: מקשה על יצירת "שפה משותפת" שאנשים זוכרים וחולקים.
אז מה הופך מערכת להיות Event-Driven? - לא תצאו עם תשובה חד משמעית מהפוסט.
יצא לי לעבוד על מערכת בה השתמשנו בכל ארבעת הגישות, ולרגע לא חשבתי לקרוא למערכת "Event Driven".... מוזר.
שיהיה בהצלחה!
---
לינקים רלוונטיים
ההרצאה של פאוולר ב Goto; Chicago
פוסט של פאוולר בנושא
ה Keynote ב Goto Chicago שהתקיים לפני מספר ימים היה של מרטין פאוולר, בו הוא ביצע סיווג של סגנונות של "Event-Driven Architecture" (או בקיצור: EDA).
יש לי באופן אישי בעיה עם ההגדרה "Event-Driven Architecture".
- האם הארכיטקטורה עצמה מונעת על ידי אירועים?
- האם באמת הפרט החשוב ביותר בארכיטקטורה הוא האירועים או כיצד הם מטופלים?
לומר ש "יש לנו ארכיטקטורה שהיא Event-Driven" זה כמעט כמו לומר "יש לנו ארכיטקטורה שהיא Database Driven" או "ארכיטקטורה שהיא Java Driven". כלומר:
א. אנחנו מציינים כלי - ולא פרט מרכזי על מבנה המערכת.
ב. באמת, שלא ניתן ללמוד שום-דבר מהאמירה הזו.
בכלל, ככל שמערכת גדלה, ובמיוחד כאשר היא נעשית מבוזרת - יותר סביר שנשתמש באירועים איפשהו במערכת. האם זה הופך את המערכת שלנו ל Event-Driven?
ובכן... מדוע אנשים מציינים שיש להם "Event Driven Architecture"? כנראה כי:
א. זה נשמע "טוב". באזז מרשים.
ב. כי אותם אנשים מרוצים מהשימוש ב events - ונתונים לתכונה הזו של המערכת דגש מיוחד.
ראיתי מערכת או שתיים בחיים, שבאמת לא הייתה בהן כמעט תקשורת סינכרונית, וכמעט הכל טופל ב events. המודל הזה יכול להיות יעיל מאוד ל load גבוה, כאשר יש שורה של שלבים בעיבוד נתונים.
הייתי קורא למערכת כזו "Event Based", ומנסה להבין מה מניע את המערכת והארכיטקטורה שלה. האם מדובר ב Scalability? האם חלוקה של תהליך עיבוד ליחידות קטנות ופשוטות יותר?
אז למה באמת מתכוונים ב "Event-Driven Architecture"?
אם נחפש קצת בספרות מקצועית, נוכל למצוא הגדרות כמו זו:
 |
| מתוך הספר Event-Driven Architecture: How SOA Enables the Real-Time Enterprise |
אני לא רוצה להיות מרושע, אבל באמת זו חתיכת פסקה ארוכה שלא אומרת הרבה...

בספרון של מארק ריצ'רדס בשם Software Architecture Patterns הוא מתאר שני סוגים עיקריים של EDA:
- Mediator Topology - בה יש "מח" מרכזי שיודע איזה שלבים יש לכל event, אלו ניתן למקבל וכו'- והוא זה שמנהל אותם
- Broker Topology - בה החוכמה היא "מבוזרת" וכל רכיב שמטפל ב event יודע מה היעד הבא של ה Event / או אילו events חדשים יש לשלוח.
הוא בוחן את נקודות החוזק והחולשה בכל גישה - וזה נחמד, אך הוא עדיין לא ממש מספק תמונה שמכסה את השימושיים העיקריים של events במערכות תוכנה.
קצת עזרה??
כאן באמת הסשן של פאוולר היה מוצלח, ולכן החלטתי שהוא שווה פוסט. פאוולר הוא אולי לא המתכנת המבריק ביותר, אולי לא הארכיטקט הראשון לתכנון מערכות - אבל קשה לי לחשוב על דמות טכנולוגית שיודעת לקחת חומר טכני ולהנגיש אותה לקהל - בצורה טובה כמוהו.
פאוולר מגדיר ארבעה צורות עיקריות לשימוש ב Events במערכת. אם נשתמש במונחים הללו, ולא במונח הכללי "Event-Driven Architecture" - הרי נוכל להבין טוב יותר אחד את השני.
Event Notification

זה המקרה הפשוט בו אני רוצה להעביר הודעה בין מודול א' למודול ב' בצורה אסינכרונית.
למשל:
- אפליקציית הנהג מודיעה שהסיעה הסתיימה.
- המערכת לניהול נסיעות סוגרת את הנסיעה ושולחת הודעה שהנסיעה הסתיימה.
הקריאה היא אסינכרונית בפועל: אין צורך להמתין לחיוב שהתבצע - אלא רק ל Queue שהוא אכן קיבל את ההודעה. אם מערכת החיוב פונה לחברות האשראי ייתכן שייקח לה מספר שניות לבצע את החיוב, בעוד Queue יקבל את ההודעה ב מילישניות בודדות. - מערכת החיוב בודקת את ה Queue כל הזמן אם יש הודעת. כאשר היא שולפת הודעות - היא מטפלת בהן ב"זמנה החופשי".
המודל של Event Notification הוא פשוט ושימושי.
- הוא מתאים כאשר מישהו רוצה לשלוח הודעה והוא לא מצפה לתשובה.
- הוא מתאים כאשר הצד מרוחק יבצע את הפעולה בקצב שונה. למשל: בשל תקלה בחברת כרטיסי האשראי ייתכן שהחיוב יתבצע רק לאחר שעה (דוגמה קיצונית).
- הוא מאפשר למערכת ניהול הנסיעות להיות בלתי תלויה במערכת החיוב: אם יום אחד רכיב אחר יטפל בחיוב / הטיפול יחולק בין כמה רכיבים - מערכת ניהול הנסיעות לא תשתנה כתוצאה מכך.
- חוסר התלות הזו היא לא מושלמת: מה קורה כאשר מערכת החיוב זקוקה לנתון נוסף לצורך החיוב? (על כך בהמשך)
- כלל טוב לצמצום התלות הוא לשגר אירוע "כללי" שמתאר את מה שקרה במערכת "נסיעה הסתיימה" ולא פקודה כמו "חייב נסיעה!". שימוש במינוחים של פקודה גורם לנו לקבל בצורה עמוקה יותר את התלות בין המודולים - ולהעצים אותה לאורך הזמן.
- כאשר יש ריבוי של Events Notifications במערכת - קשה יותר לעקוב אחרי ה flow, במיוחד כאשר events מסוימים מתרחשים רק לפעמים ו/או במקביל.
Mitigation אפשרי הוא מערכת לוגים מרכזית ופעפוע "request id" (ואולי גם hop counter) על גבי ה events. כל כתיבה ללוג תציין את ה request id - וכך יהיה אפשר לפלטר את כל מה שהתרחש במערכת במערכת הלוגים ולראות תמונה שלמה. בערך.
עד כאן טוב ויפה.
מה קורה כאשר מערכת החיוב דורשת עוד נתון ממערכת הנסיעות? למשל: האם הנסיעה התחילה בשדה תעופה או לא?

בגישת קיצון אחת, להלן הגישה העצלה - ניתן לשלוח ב event רק את id של הנסיעה שהסתיימה. מערכת החיוב תשלים את הנתונים החסרים ממערכת הנסיעות / מערכות אחרות.
בגישת קיצון שנייה, להלן הגישה הנלהבת (eager) - אנחנו מעדכנים את ה event לכלול את כל הנתונים שמערכת החיוב זקוקה להם.
בשני המקרים, יש לנו תלות מסוימת במערכת החיוב: שינוי במערכת החיוב עלול לדרוש שינוי במערכת ניהול הנסיעות - בגרסה אחת להוסיף שדה ב API של מערכת ניהול הנסיעות, בגרסה שניה - נתון על ה event.
איזו גישה עדיפה? - אין לי תשובה חד משמעית.
בד"כ אני מעדיף את הגישה הנלהבת, כי:
- יותר קל לעקוב מה מתרחש - כי אפשר להסתכל על ה event ולהבין אלו נתונים נשלחו - ובמקום אחד.
- הערכים שעברו על ה event הם קונסיסטנטים ל event - לא יקרה מצב שבחצי שנייה (או דקה) שלוקח למערכת החיוב לבצע קריאה - אחד הערכים השתנה.
- יש פחות קריאות ברשת, ומעט פחות דברים שעשויים להשתבש.
כמובן שאם יש נתונים שצריכים להיות fresh, כדאי לערבב בין הגישות - ולקרוא אותם ברגע האמת בעזרת API.
Event-Carried State Transfer
גישה זו היא וריאציה של גישת ה Event Notification, אבל שינוי אחד בה - משנה בצורה משמעותית את כללי המשחק:

- אפליקציית הנהג מודיעה שהנסיעה הסתיימה.
- מערכת ניהול הנסיעות שולחת את כל הנתונים שיש לה על ה event.
איך שולחים את כל הנתונים? בד"כ לוקחים את אובייקט המודל של ה ORM - ועושים לו serialization. - מערכת החיוב בודקת כל הזמן אחר הודעות. כאשר יש הודעה - היא קוראת ממנה רק את הנתונים שהיא זקוקה להם. היא עשויה לשמור עותק מקומי שלהם.
בעצם במקום להעביר הודעה, אנחנו מעבירים את ה state השלם של האובייקט בין המערכות השונות.
לגישה זו כמה יתרונות:
לגישה זו כמה יתרונות:
- השגנו isolation גדול יותר (במימד אחד): שינוי במערכת החיוב לא ידרוש שינוי במערכת ניהול הנסיעות.
- Availability - אם מערכת ניהול הנסיעות קרסה, ניתן להמשיך לבצע חיובים, כי למערכת החיוב יש את כל הנתונים שהיא צריכה.
לגישה יש גם כמה חסרונות:
- שברנו את ה encapsulation: מערכת החיוב מכירה את מבנה הנתונים הפנימי של מערכת ניהול הנסיעות. מעכשיו יהיה קשה הרבה יותר לבצע שינויים במבנה הנתונים, ויש גם סכנה שהמתכנת של מערכת החיוב לא יבין את השדות נכון - ויפעל ע"פ נתונים מוטעים.
- העברנו הרבה נתונים מיותרים ברשת - בד"כ זו בעיה משנית.
- יצרנו עותקים שונים של הנתונים ברשת, מה שפוטנציאלית יוצר בעיה של Consistency בין הנתונים. נתונים שכן צריכים להיות up-to-date לצורך הפעולה - יהיו לא מעודכנים ויתכן שיהיה צורך בליישם מנגנון של eventual consistency.
שבירת ה encapsulation היא מבחינתי השבר העיקרי.
מרטין פאוולר ביטא זאת יפה, בנחמדות בריטית אופיינית: "זו גישה שטוב שתהיה בתחתית ארגז הכלים שלכם". אפשר להשתמש בה - מדי פעם.
מה קורה כאשר מידע נוסף נמצא על מערכת שלישית? למשל, את הפרט אם נסיעה התחילה בשדה תעופה (ואז יש לתת 30% הנחה ;-)) ניתן להסיק רק כאשר יש נתונים נוספים ממערכת האזורים?
גם כאן יש בחירה: אפשר לתת את המשימה למערכת ששולחת את ה event, או לזו שמקבלת אותו. כנראה הבחירה תעשה ע"פ איזו תלות בין המערכות - היא סבירה יותר.

Event Sourcing
הרעיון בגישה זו היא שאנו שולחים אירועים על שינוי state של האובייקט, אבל ה event מכיל רק את השינוי הספציפי - ה delta. אנחנו גם מאחסנים את הנתונים בצורה הזו.
לצורך העניין אין מחיקות או דריסות של שדות - רק שורה של שינויים באובייקט.

אם מישהו רוצה לקרוא את האובייקט - הוא צריך להרכיב את שרשרת השינויים בכדי לקבל את האובייקט העדכני.
מה התועלת בגישה הזו?
- אם אנחנו מקבלים עדכוני state מכמה מקורות - אין לנו race condition בו מקור א' מוחק את השינוי של מקור ב'.
זה יכול להתרחש אם מקור א' קרא עותק ישן של האובייקט, לפני השינוי שמקור ב' ביצוע - אבל ההודעה ממנו הגיעה אחריו. - אנחנו שומרים היסטוריה של האובייקט ושינויי המצב שלו. אם נרצה - נוכל להרכיב את מצב האובייקט בכל רגע נתון (בהנחה ששמרנו את הזמן שבו קיבלנו את ההודעה).
- זה יכול להיות שימושי לצורך debugging / הסבר התנהגות המערכת.
- ההודעות שנשלחות הן קטנות (רלוונטי כאשר האובייקט השלם הוא גדול)
יש גם כמה חסרונות:
- הרכבה של האובייקט, במיוחד אם קיבל רשימה ארוכה של עדכונים - היא פעולה יקרה יחסית.
- החיסרון הזה הוא בעייתי במיוחד אם הרכבה של האובייקט דורשת נתונים נוספים ממערכות אחרות.
- החיסרון הזה מתמתן אם אנחנו מחזיקים עותק של הנתונים בזיכרון.
- מה קורה כאשר הסכמה משתנה? כלומר: מבנה הנתונים?
פה עשויה לעלות שאלה פילוסופית: אם אני מקבל את העדכונים כ delta, אבל אז בכל עדכון עושה merge עם האובייקט שאני מחזיק אצלי - האם זה עדיין Event Sourcing?
אפשר לומר שכן - ההצהרה הזו עדיין תעזור לאנשים לקבל במשפט אחד תובנה על המערכת. מניעת racing condition הוא ערך גדול בפני עצמו. יש פה tradeoff כמובן: ביטול חסרונות משמעותיים - מול איבוד כמה מהיתרונות האחרים. זהו tradeoff סביר לחלוטין.
Command Query Responsibility Segregation (בקיצור: CQRS)
מספרים שאם הייתם מחפשים בגוגל "CQRS" לפני עשור, הוא היה שואל: "`?did you mean `Cars"
הרעיון הוא דיי ישן, ומקורו בשנות השמונים, אבל רק בשנים האחרונות הוא הפך למאוד-מוכר.
אני מניח שהרוב הגדול של הקוראים מכיר את השם, אבל לא בהכרח מכיר את הרעיון מאחוריו. לרוב האנשים CQRS מתקשר ל "high performance".
האמת שהרעיון של CQRS אינו קשור קשר ישיר ל events, אבל פעמים רבות - משתמשים בו כך.
הרעיון בגדול אומר:
קיים מודל אחד לכתיבה של אובייקט, ומודל נפרד לקריאה של אובייקט.

מתי זה שימושי?
כאשר דפוס הקריאה ודפוס הכתיבה שונים זה מזה.
למשל: נניח בטוויטר (אני מספר מהזיכרון - ייתכן שזה לא מה שקורה שם) כתיבה של טוויט (להלן: Command) הולכת למודל הכתיבה. שחררתי את הטוויט מהר והמשכתי לאינסטגרם.
כאשר משתמש אחר נכנס לטוויטר, הוא רוצה לראות את הפיד של הטוויטים מיד. אם נתחיל לעשות Query אחר כל האנשים שהוא עוקב אחריהם, וכל הטוויטים שלהם, ואז נמיין אותם ע"פ הסדר -זה ייקח הרבה זמן! יותר מדי.
במקום זה, לאחר שכתבתי את ה tweet יש Background Processor שמעתיק את הטוויט שלי לפיד של כל העוקבים.
כלומר:
- מודל "הכתיבה" הוא רשימה של טוויטים ע"פ מחבר.
- מודל "הקריאה" הוא הפיד של כל משתמש בנפרד.
זה אומר שיש הרבה שכפול נתונים במערכת, ושטח האחסון הנדרש הוא אדיר. אם יש למישהו מיליון עוקבים - כל טוויט ישוכפל מיליון פעמים.
מצד שני, זה גם אומר שגם אם אני עוקב אחרי 1000 פרופילים ויותר - הפיד שלי ייטען ב (O(1.
במקרה של טוויטר סביר שמודל הכתיבה ומודל הקריאה הן בכלל מערכות שונות - כאשר כל הוספה של טוויט למודל הכתיבה - שולחת אירוע של עדכון (event notification) למודל הקריאה - שם נמצא ה Background processor.
במקרה של טוויטר סביר שמודל הכתיבה ומודל הקריאה הן בכלל מערכות שונות - כאשר כל הוספה של טוויט למודל הכתיבה - שולחת אירוע של עדכון (event notification) למודל הקריאה - שם נמצא ה Background processor.
מכיוון שלא ממש משנה אם אני מקבל את הטוויטים מיד או אחרי דקה או שתיים מרגע שצויצו, ומכיוון שלא כ"כ משנה עם הסדר של הטוויטים אצלי הוא אותו סדר כמו אצל חבר שלי העוקב אחרי בדיוק אותם פרופילים - המודל הזה עובד.
כמובן שאפשר לעשות וריאציית משנה, ולשכפל רק את ה ids של הטוויטים.
הקריאה תארוך קצת יותר זמן - אבל נפח האכסון יקטן בצורה משמעותית.
כמובן שאפשר לעשות וריאציית משנה, ולשכפל רק את ה ids של הטוויטים.
הקריאה תארוך קצת יותר זמן - אבל נפח האכסון יקטן בצורה משמעותית.
שימוש אחר של CQRS הוא לא דווקא מבחינת ביצועים גבוהים, אלא פשטות של הקוד. אם המודלים סבוכים למדי - החלוקה ל"מודל כתיבה" ו"מודל קריאה" יקטינו את ה code base בחצי, בערך.
כאן שווה לציין ש Event Sourcing ו CQRS הולכים יד ביד זה עם זה:
מודל הכתיבה הוא ה State Log - אבל יש מודל קריאה שהוא המצב העדכני. זה יכול להיות בסיס נתונים או טבלה אחרת בה שומרים את המצב העדכני, וזה יכול להיות מודל שעובד מעל אותם נתונים - ורק מכיל את הקוד של "השטחת" העדכונים בזמן ה Query.
סיכום
התלהבתי מהסדר שפאוולר עשה בנושא ה Event-Driven, ולכן כתבתי את הפוסט והוספתי עוד כמה תובנות משלי.
השארתי קצת אפור בהגדרות של הגישות השונות. תמיד ניתן לערבב ולייצר וריאציות. למשל:
הייתי מעורב בבניית מערכת שמבצעים בה רפליקציה של נתונים לשירותים אחרים, כמו בגישת ה Event-Carried State Transfer - בכדי להשיג High Availability. מצד שני, כמות הנתונים שמועתקת היא קטנה ומדודה מאוד, והנתונים הם ברמת הפשטה של ממשק ולא מבנה נתונים פנימי - כך שאין פגיעה בהכמסה של המערכת.
אם הייתי מנסה לתעד כל וריאציה שימושית בפני עצמה - כנראה שהיינו גומרים עם 16 צורות לשימוש ב Events ולא ארבעה, מה שהיה מאריך את הפוסט אבל יותר גרוע: מקשה על יצירת "שפה משותפת" שאנשים זוכרים וחולקים.
אז מה הופך מערכת להיות Event-Driven? - לא תצאו עם תשובה חד משמעית מהפוסט.
יצא לי לעבוד על מערכת בה השתמשנו בכל ארבעת הגישות, ולרגע לא חשבתי לקרוא למערכת "Event Driven".... מוזר.
שיהיה בהצלחה!
---
לינקים רלוונטיים
ההרצאה של פאוולר ב Goto; Chicago
פוסט של פאוולר בנושא