בפוסט זה אני רוצה לדבר על Pipes And Filters (בעברית: "צינורות ומסננים", בקיצור: PAF).
אז מה זה PAF?
PAF יכול להיות סגנון ארכיטקטוני - במידה ויש מערכת שרובה בנויה בצורה זו. אם עוסקים במודול במערכת - אזי ניתן להתייחס ל PAF כ Design Pattern. באופן כללי - זהו רעיון.
אנו נתייחס אליו כרעיון, בכדי לא לתת לבאזז ("סגנון ארכיטקטוני") להסיט אותנו מהעיקר.
כמו רעיונות אחרים, PAF הוא לא רעיון ייחודי לגמרי לעולם המחשוב, או כזה שניתן לטעון שעולם המחשוב "המציא" אותו. הרעיון של PAF הוא לחלק תהליך מורכב לחלקים פשוטים ונשלטים, ובצורה סטנדרטית - על מנת להפוך אותו פשוט יותר ליישום.
כאשר יש תהליך לעיבוד חומר (כימיקלים, למשל) ישנו תהליך קווי של פעולות ההופכות כמה חומרי גלם X1,...,Xn לחומר רצוי אחר Z. בד"כ פס ייצור שכזה בתעשייה הכימית יראה כקו או "עץ לוגי" עם מספר מיכלים (מערבלים, ראקטורים, מסננים וכו') המחוברים בצינורות. במיכלים מתבצע שינוי בחומר או חיבור של כמה חומרים שונים. הצינורות נועדו בכדי להעביר את החומרים משלב לשלב בצורה יעילה.
מבנה צורני (="ארכיטקטורה") זה יכול לתאר גם תהליך חישובי:
בתעשייה הכימית יש כמה הבדלים:
כשאנו מגדירים ארכיטקטורה של תוכנה או של מודול בתוכנה, אנו לרוב אוהבים לעשות את זה בעזרת כלים מתוחכמים:
ב UNIX / לינוקס משתמשים ב PAF באופן מובנה, בעבודה השוטפת ב Console קרי Bash (או וריאציות דומות).
למשל פקודה בסיסית כמו:
היא בעצם יישום של רעיון ה Pipes and Filters, כאשר התוכנות find ו grep הן המסננים ויש סט של צינורות (pipes) מובנים ב shell.המסננים ביוניקס הם מן הסתם אקטיביים (נוצר תהליך OS process) עבור כל תוכנה ברצף ה PAF. יש מספר pipes זמינים כאשר כל אחר מתנהג מעט אחרת ( | = מעביר עותק כקלט, < = שכתוב, << = הוספה, וכו'). הממשק בין pipe ל filter היא stream של נתונים. ה datasync הוא בד"כ קובץ או פלט על המסך.
אפשר לציין גם את כלי ה build שנקרא Gulp, שבנוי בארכיטקטורה של PAF: תהליך ה build הוא בדיוק כזה שאנו רוצים לשנות בקלות ע"י "תפירה מחדש" של ה pipes. את הכתיבה לדיסק (temp files, compilations - למשל כמו שמתרחשת ב Maven או Grunt) מחליפים ב pipes בזיכרון כך ש:
דוגמה אחרונה, ומאוד מייצגת היא מערכת / Framework בשם Apache Storm (לשעבר של טוויטר) לביצוע חישובים / ניתוח נתונים בזמן אמת (realtime). האמת, שזה לא ממש realtime (גם אם כמה עשרות ms - זה עדיין לא "realtime") ואני מעדיף לקרוא לה "מערכת לניתוח נתונים ב latency נמוך".
Storm היא סוג של התממשות הסגנון הארכיטקטוני של PAF, ומעט יותר. הוא בעצם מאפשר, בצורה מאוד קלה ומהירה להרים רשת (בטרמינולוגיה של Storm - "טופולוגיה") של pipes and filters ולהריץ אותה מול data sources שונים (מימושים שמגיעים OOTB יכולים להתחבר ל Kerstel, JMS, Redis pubsub וכו'), בעזרת מה שנקרא Spouts (תרגום חופשי: "פיה של ברז") - סוג של Adapter למקור המידע.
אמנם החלוקה ל Pipe ו Filter היא לא בדיוק ע"פ ההגדרה הקלאסית: ה Filter ב Storm (נקרא bolt - בורג) הוא זה שבעצם מגדיר את ה Stream Grouping, להיכן וכיצד להעביר את הפלט שלו (שזה סוג של Pipe). האמת שחיפשתי בגוגל אחר Apache Storm בהקשר של Pipes and Filters - ולא מצאתי שומדבר. האם אני היחידי שרואה את הקשר החזק?!
הממשק של Storm הוא של tuples - רשימות של ערכים (דומה ל HashMap, מפתחות וערכים) אותן מעבדים. כל bolt יכול להמיר את ה tuples, לפלטר אותם (להעביר הלאה רק חלק) או לבצע עליהן סיכומים (למשל: ספירה או ממוצע של הערכים שהוא ראה).
בניגוד ל Bash, למשל, שם ה PAF הוא מקומי וקטן מימדים, טופולוגיה של Storm יכולה להכיל הרבה מאוד nodes, על גבי cluster, שיעסיק הרבה מאוד CPU cores. חלק לא קטן מההתעסקות ב Storm היא התאמה של הטופולוגיה ל cluster שכזה ויישום אופטימיזציות ביצועים / חלוקת משאבים / ניטור ופתרון בעיות וכו'. Storm גם מתמודדת עם נושאים של Fault Tolerance, שאינם חלק מ PAF (דומה בהיבט זה מעט יותר ל Hadoop). שלושת התסריטים הנפוצים לפתור בעזרת Storm הם:
דנו בתבנית עיצוב / תבנית ארכיטקטונית / סגנון ארכיטקטוני / רעיון של Pipes and Filters. זהו סגנון מעט לא שגרתי, שלא כ"כ מתאים לרוב בעיות התכנות שעומדות בפנינו, אבל לפעמים כאשר הוא באמת מתאים - הוא יכול לעבוד יפה מאוד.
אחד הדגשים שלו, שלפעמים שוכחים, הוא גמישות ל"חיווט מחדש" ולא רק פישוט הבעיה או שימוש-חוזר בקוד.
כמו כל תבנית עיצוב / ארכיטקטורה - הוא יכול להישמע מאוד מוצלח, אבל זה לא אומר שכדאי לכם עכשיו לעזוב הכל ולאמץ אותו. זהו כלי שטוב למשימות מסוימות ולא מתאים למשימות אחרות. מסורית היא כלי עבודה נהדר - לחיתוך מתכת, אבל לא כ"כ כדי לדפוק מסמרים בקיר. חבל להתעקש ולנסות.
שיהיה בהצלחה!
אז מה זה PAF?
- האם זהו סגנון ארכיטקטוני?
- אולי Design Pattern?
- אולי סתם רעיון?
PAF יכול להיות סגנון ארכיטקטוני - במידה ויש מערכת שרובה בנויה בצורה זו. אם עוסקים במודול במערכת - אזי ניתן להתייחס ל PAF כ Design Pattern. באופן כללי - זהו רעיון.
אנו נתייחס אליו כרעיון, בכדי לא לתת לבאזז ("סגנון ארכיטקטוני") להסיט אותנו מהעיקר.
כמו רעיונות אחרים, PAF הוא לא רעיון ייחודי לגמרי לעולם המחשוב, או כזה שניתן לטעון שעולם המחשוב "המציא" אותו. הרעיון של PAF הוא לחלק תהליך מורכב לחלקים פשוטים ונשלטים, ובצורה סטנדרטית - על מנת להפוך אותו פשוט יותר ליישום.
 |
| "צינורות ומסננים" בתהליך כימי. שם הבידוד הוא תנאי הכרחי לקיום התהליך - לפעמים. |
צינורות ומסננים - כמטאפורה
כאשר יש תהליך לעיבוד חומר (כימיקלים, למשל) ישנו תהליך קווי של פעולות ההופכות כמה חומרי גלם X1,...,Xn לחומר רצוי אחר Z. בד"כ פס ייצור שכזה בתעשייה הכימית יראה כקו או "עץ לוגי" עם מספר מיכלים (מערבלים, ראקטורים, מסננים וכו') המחוברים בצינורות. במיכלים מתבצע שינוי בחומר או חיבור של כמה חומרים שונים. הצינורות נועדו בכדי להעביר את החומרים משלב לשלב בצורה יעילה.
מבנה צורני (="ארכיטקטורה") זה יכול לתאר גם תהליך חישובי:
- קבל XML
- שאב ממנו נתונים מסוים
- העבר אותם המרה
- שלב אותם עם נתונים ממקור אחר
- העבר את המבנה החדש עיבוד נוסף (למשל: פילטור ערכים ריקים או formatting)
- טא-דם: יש לנו נתונים בעלי ערך / משמעות גבוהים יותר
בתעשייה הכימית יש כמה הבדלים:
- חלק מהתוצר הוא פסולת - שיש להיפטר ממנה בצורה מסודרת.
- יש איבוד חומר (מסוים) בתהליך.
- לא ניתן "לשכפל חומר" - כפי שמשכפלים נתונים. חוק שימור המאסה.
- ישנם תהליכים שמבחינה כימית לא ניתן להפריד לשלבים נפרדים.
- אפשר להתלכלך / לקבל סרטן / או סתם לגרום לפיצוץ או שריפה - אם טועים בחישוב.
איזה כיף לעבוד בעולם לוגי - ללא כל הקשיים הללו :)
"צינורות ומסננים" כתהליך פיתוח תוכנה
כשאנו מגדירים ארכיטקטורה של תוכנה או של מודול בתוכנה, אנו לרוב אוהבים לעשות את זה בעזרת כלים מתוחכמים:
- תבניות עיצוב - יש!
- טכנולוגיה חדישה - יש!
- ספריות Open Source לוהטות - למה לא?!
- תרשימים מורכבים, שנרגיש שעבדנו קשה - בטח!
- קצת תיבול: "גנרי", "פלאג-אינים" ו"הכנות למזגן" - אי אפשר בלי!
אם "מקרים קיצוניים דורשות פתרונות קיצוניים" (בערך), אז אולי "בעיות מורכבות דורשות כלים מורכבים?"
זהו - אז שלא תמיד.
כשיש בעיה שקשה לפתור - אחד הכלים שאני משתמש בו לעתים הוא לעקוב אחרי הנתונים.
"תפסיקו לחשוב על מיפוי קאנוני של הרשאות" - אני אומר. "אנו רוצים להגיע ממבנה בזיכרון של X1 למבנה Z1, נכון? ומ X2 ל Z2? - בואו נסתכל על הנתונים בצורה הכי רדודה וננסה לבצע, בצעדים פשוטים, את הטרנספורמציה".
יש איזו הרגשת חמיצות באוויר כשעובדים כך: זה לא מרגיש כמו "ארכיטקטורת תוכנה", אלא כמו מה שמהנדס תוכנה פשוט וחסר מעוף היה עושה. וזה עובד! עובד טוב - אפילו!
כשלב מאוחר יותר, לאחר שיש פתרון שעובד - ניתן לנסות ל"תחכם" ולייעל / לפשט את המבנה.

PAF הוא גם תיאור של מבנה של תוכנה. מבנה זה יתאים ל:
ארכיטקטורת PAF שכזו היא לא רק רשת של פונקציות חישוביות שמעבירות ביניהם נתונים - היא נבנתה בכדי לערוך / ליצור קשרים חדשים בין הפונקציות בקלות ובמהירות. היא עושה בעצם את ה tradeoff הבא:
זהו - אז שלא תמיד.
כשיש בעיה שקשה לפתור - אחד הכלים שאני משתמש בו לעתים הוא לעקוב אחרי הנתונים.
"תפסיקו לחשוב על מיפוי קאנוני של הרשאות" - אני אומר. "אנו רוצים להגיע ממבנה בזיכרון של X1 למבנה Z1, נכון? ומ X2 ל Z2? - בואו נסתכל על הנתונים בצורה הכי רדודה וננסה לבצע, בצעדים פשוטים, את הטרנספורמציה".
יש איזו הרגשת חמיצות באוויר כשעובדים כך: זה לא מרגיש כמו "ארכיטקטורת תוכנה", אלא כמו מה שמהנדס תוכנה פשוט וחסר מעוף היה עושה. וזה עובד! עובד טוב - אפילו!
כשלב מאוחר יותר, לאחר שיש פתרון שעובד - ניתן לנסות ל"תחכם" ולייעל / לפשט את המבנה.
"צינורות ומסננים" כארכיטקטורה / סגנון ארכיטקטוני
PAF הוא גם תיאור של מבנה של תוכנה. מבנה זה יתאים ל:
- "מנוע חישובי" - בו יש הרבה פעולות לוגיות של חישוב ומעט / ללא אינטגרציה למערכות אחרות או I/O.
- חישוב מסובך אותו נרצה "לפרק" ליחידות קטנות ("Divide and Conquer") בכדי לפשט.
- חישוב נתונים ב stream - כאשר המידע מגיע בהדרגה או גדול מדי בכדי להכיל בזכרון.
- מערכת בה נרצה לעשות שינויים בדרכי עיבוד הנתונים, על בסיס הפונקציות שכבר קיימות ("חיווט מחדש") או ע"י הוספת פונקציות.
ארכיטקטורת PAF שכזו היא לא רק רשת של פונקציות חישוביות שמעבירות ביניהם נתונים - היא נבנתה בכדי לערוך / ליצור קשרים חדשים בין הפונקציות בקלות ובמהירות. היא עושה בעצם את ה tradeoff הבא:
גמישות לשינויים בצורת החישוב + עלות תחזוקה נמוכה (לשינויי "חיווט") > ביצועים
ארכיטקטורת PAF היא בד"כ איננה הדרך היעילה ביותר (מבחינת ניצלות משאבים) לבצע את החישוב: יש העתקות רבות בזיכרון, cache trashing של זיכרונות המטמון במעבד, לפעמים context switch מרובים וכו'. במעבדים המוכרים לנו, עיבוד נתונים ב "batch" (ליתר דיוק batch לכל core של המעבד) הוא לרוב יעיל יותר.
הנה class diagram המתאר את PAF בצורה פורמלית:

והנה object diagram שאולי מעט יותר מוחשי לצורך ההבנה:
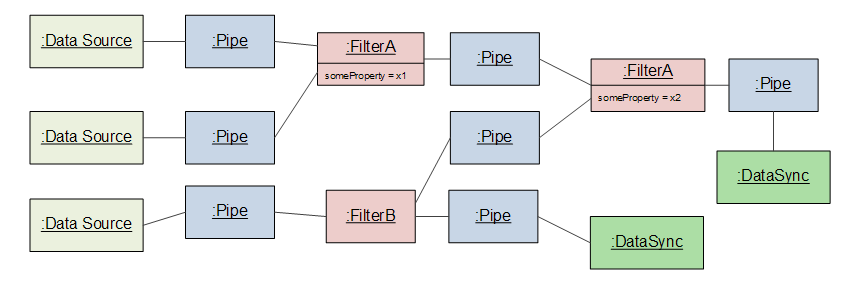
הנה class diagram המתאר את PAF בצורה פורמלית:
והנה object diagram שאולי מעט יותר מוחשי לצורך ההבנה:
מתי כדאי לשקול ארכיטקטורת PAF?
מתי שאפשרמתי שיש תהליך חישובי- מתי שיש תהליך חישובי - אך הוא לא מגובש / צפוי לשינויים תמידיים.
- מתי שיש תהליך חישובי, שכבר נותן ערך - אך קשה לתחזק אותו.
עכשיו, אין פה פרות קדושות מבחינתי: אפילו אם Design Pattern מוגדר בצורה מסוימת - זו רק המלצה.
רבים מהמפעלים הכימיים (למיטב ידיעתי) לא בנויים בצורה מודולרית - וקשה לעשות בהם שינויים בתהליך (לטובת יתרונות אחרים של יעילות / אופטימיזציית התהליך). באופן דומה, אפשר להשתמש במבנה של PAF ללא החלק המודולרי / ממשקים אחידים ל Pipes או Filters: רק בכדי לפשט ולאפשר שליטה טובה יותר בתהליך חישובי ארוך או מסובך. בארכיטקטורה כמו בארכיטקטורה: הכל תלוי במאפיינים הייחודים של המערכת שלכם - וכיצד תומכים בהם בצורה טובה יותר.
למרות המבנה המוגדר-היטב של PAF, יש עוד מקום רב להחלטות או וריאציות:
רבים מהמפעלים הכימיים (למיטב ידיעתי) לא בנויים בצורה מודולרית - וקשה לעשות בהם שינויים בתהליך (לטובת יתרונות אחרים של יעילות / אופטימיזציית התהליך). באופן דומה, אפשר להשתמש במבנה של PAF ללא החלק המודולרי / ממשקים אחידים ל Pipes או Filters: רק בכדי לפשט ולאפשר שליטה טובה יותר בתהליך חישובי ארוך או מסובך. בארכיטקטורה כמו בארכיטקטורה: הכל תלוי במאפיינים הייחודים של המערכת שלכם - וכיצד תומכים בהם בצורה טובה יותר.
למרות המבנה המוגדר-היטב של PAF, יש עוד מקום רב להחלטות או וריאציות:
- מהם ה Filters, האם אלו threads בלולאה? האם הם עושים pull מה pipe שמזין אותם או שה pipe עושה push ואולי מספק את ה thread?
- אולי בכלל מדובר על event loop יחיד לכל המערכת ללא threads?
- מהם ה pipes? האם הם streams בזיכרון, או אולי פשוט channel של events?
- כיצד מתמודדים עם concurrency של Filters אקטיביים. כיצד עושים זאת ללא תקורה משמעותית?
- הגדרת הממשקים בין ה pipes וה filters (במיוחד כאשר רוצים מערכת שניתנת לשינויים בקלות / מאפשרת שימוש חוזר ב filters)
- כיצד מטפלים ב error handling / מתאוששים מנתונים לא תקניים (מכיוון שהמערכת מחולקת ליחידות בלתי-תלויות - עניין זה הופך למורכב יותר)
- ועוד
דוגמאות מעשיות לשימוש בארכיטקטורת "צינורות ומסננים"
ב UNIX / לינוקס משתמשים ב PAF באופן מובנה, בעבודה השוטפת ב Console קרי Bash (או וריאציות דומות).
למשל פקודה בסיסית כמו:
find /var -name "*log*" | grep log
היא בעצם יישום של רעיון ה Pipes and Filters, כאשר התוכנות find ו grep הן המסננים ויש סט של צינורות (pipes) מובנים ב shell.המסננים ביוניקס הם מן הסתם אקטיביים (נוצר תהליך OS process) עבור כל תוכנה ברצף ה PAF. יש מספר pipes זמינים כאשר כל אחר מתנהג מעט אחרת ( | = מעביר עותק כקלט, < = שכתוב, << = הוספה, וכו'). הממשק בין pipe ל filter היא stream של נתונים. ה datasync הוא בד"כ קובץ או פלט על המסך.
 |
| Pipes and Filters כפי שמומשו ב Unix. מקור: Ariel Ortiz Ramírez |
אפשר לציין גם את כלי ה build שנקרא Gulp, שבנוי בארכיטקטורה של PAF: תהליך ה build הוא בדיוק כזה שאנו רוצים לשנות בקלות ע"י "תפירה מחדש" של ה pipes. את הכתיבה לדיסק (temp files, compilations - למשל כמו שמתרחשת ב Maven או Grunt) מחליפים ב pipes בזיכרון כך ש:
- לא כותבים לדיסק --> תהליך ה build מהיר יותר.
- הימנעות מקבצי ה build הזמניים --> אין מה "לנקות" / אין צורך בשלב "clean" = פחות תקלות והתעסקויות.
 |
| היתרון של Gulp. מקור: http://slides.com/contra/gulp |
דוגמה אחרונה, ומאוד מייצגת היא מערכת / Framework בשם Apache Storm (לשעבר של טוויטר) לביצוע חישובים / ניתוח נתונים בזמן אמת (realtime). האמת, שזה לא ממש realtime (גם אם כמה עשרות ms - זה עדיין לא "realtime") ואני מעדיף לקרוא לה "מערכת לניתוח נתונים ב latency נמוך".
Storm היא סוג של התממשות הסגנון הארכיטקטוני של PAF, ומעט יותר. הוא בעצם מאפשר, בצורה מאוד קלה ומהירה להרים רשת (בטרמינולוגיה של Storm - "טופולוגיה") של pipes and filters ולהריץ אותה מול data sources שונים (מימושים שמגיעים OOTB יכולים להתחבר ל Kerstel, JMS, Redis pubsub וכו'), בעזרת מה שנקרא Spouts (תרגום חופשי: "פיה של ברז") - סוג של Adapter למקור המידע.
אמנם החלוקה ל Pipe ו Filter היא לא בדיוק ע"פ ההגדרה הקלאסית: ה Filter ב Storm (נקרא bolt - בורג) הוא זה שבעצם מגדיר את ה Stream Grouping, להיכן וכיצד להעביר את הפלט שלו (שזה סוג של Pipe). האמת שחיפשתי בגוגל אחר Apache Storm בהקשר של Pipes and Filters - ולא מצאתי שומדבר. האם אני היחידי שרואה את הקשר החזק?!
הממשק של Storm הוא של tuples - רשימות של ערכים (דומה ל HashMap, מפתחות וערכים) אותן מעבדים. כל bolt יכול להמיר את ה tuples, לפלטר אותם (להעביר הלאה רק חלק) או לבצע עליהן סיכומים (למשל: ספירה או ממוצע של הערכים שהוא ראה).
בניגוד ל Bash, למשל, שם ה PAF הוא מקומי וקטן מימדים, טופולוגיה של Storm יכולה להכיל הרבה מאוד nodes, על גבי cluster, שיעסיק הרבה מאוד CPU cores. חלק לא קטן מההתעסקות ב Storm היא התאמה של הטופולוגיה ל cluster שכזה ויישום אופטימיזציות ביצועים / חלוקת משאבים / ניטור ופתרון בעיות וכו'. Storm גם מתמודדת עם נושאים של Fault Tolerance, שאינם חלק מ PAF (דומה בהיבט זה מעט יותר ל Hadoop). שלושת התסריטים הנפוצים לפתור בעזרת Storm הם:
- Stream Processing - חישוב מתמשך של נתונים המגיעים מ (Stream(s. אולי התסריט הקלאסי ביותר.
- תסריט של Distributed RPC - לחלוקת עבודה בין מחשבים שונים.
- Continuous Computation (חישוב מתמשך) - למשל חישוב טרנד שכל רגע משנה כיוון ועצמה, על בסיס stream של נתונים.
 |
| אילוסטרציה של טופולוגיה (פשוטה) ב Storm. הקוביות הצהובות הם ה tuples על ה streams. בצד ימין יהיו ה data sync, פעמים רבות יהיה זה cassandra, או בסיס נתונים דומה. |
סיכום
דנו בתבנית עיצוב / תבנית ארכיטקטונית / סגנון ארכיטקטוני / רעיון של Pipes and Filters. זהו סגנון מעט לא שגרתי, שלא כ"כ מתאים לרוב בעיות התכנות שעומדות בפנינו, אבל לפעמים כאשר הוא באמת מתאים - הוא יכול לעבוד יפה מאוד.
אחד הדגשים שלו, שלפעמים שוכחים, הוא גמישות ל"חיווט מחדש" ולא רק פישוט הבעיה או שימוש-חוזר בקוד.
כמו כל תבנית עיצוב / ארכיטקטורה - הוא יכול להישמע מאוד מוצלח, אבל זה לא אומר שכדאי לכם עכשיו לעזוב הכל ולאמץ אותו. זהו כלי שטוב למשימות מסוימות ולא מתאים למשימות אחרות. מסורית היא כלי עבודה נהדר - לחיתוך מתכת, אבל לא כ"כ כדי לדפוק מסמרים בקיר. חבל להתעקש ולנסות.
שיהיה בהצלחה!
מהם ה pipes? האם אם streams בזיכרון
השבמחקכנראה התכוונת האם הם
נכון - תודה! תיקנתי.
מחקהאם פילטר הוא סוג של דקורטור?
השבמחקבכל מקרה זה נשמע לי מאוד דומה לרעיון של filter בwordpress...
האם זה נכון?
היי stuk,
מחקמהמעט שקראתי על פילטרים ב WordPress - זה נראה לי אותו עקרון / pattern, רק שב PAF משרשרים פילטרים, בצורה מודולרית, אחד על השני להשגת אפקט של הרבה פילטרים.
דקורטור הוא מעט שונה: אין לו משמעות בפני עצמו (כמו פילטר), אלא הוא רק "מורכב" על אובייקט קיים אחר בכדי להעשיר אותו מבלי לשנות או הקוד של האובייקט המקורי. (מה שתואם לרעיון שנקרא "העקרון הפתוח-סגור", איך להרחיב את התוכנה מבלי לסכן את היציבות שלה. רעיון זה מאבד פופולריות בשנים האחרונות).
היי ליאור,
השבמחקיופי של פוסט.
ניתן לומר שכל הארכיקטורות והמתודולוגיות המודרניות מחפשות לעזור לך ב Reuse ובארגון הלוגיקה על ידי OO. במקרה של עיבוד נתונים ההבדל הוא שאתה רוצה לתפור את הלוגיקה לא על ידי קוד אלא על ידי קבצי קונפיגורציה שלא ידרשו קומפילציה ואף תוכל לבנות איזה UI פשוט ל "טכנאים" שיוכלו לבנות זאת בצורה עצמאית "בשטח". אנחנו משתמשים בכלי דומה שנקרא apache camel שבנוי בצורה דומה ומאפשר לתפור Routes בצורה קלה. חשוב לציין שכאשר הכלי מגיע עם יכולות מובנות לעבודה עם CSV, REST וכדומה זה מקצר את הדרך אפילו עוד, ותידרש תמיכה בקוד רק בנתונים קניניים לארגון.
אלה צינורות גדולים וצבעוניים
השבמחק