היבט חשוב של תפעול ועבודה עם מערכת הם הלוגים (log files) של המערכת ואפליקציות השונות.
משמעות המילה log, כדרך אגב, היא "בול עץ". כיצד בולי-עץ קשורים לקבצי log? הנה סיפור קצר:
בעבר ניווט בים נעשה ע"י סכימת מרחקי שיט שהספינה עברה. הספינה יצאה מנמל (עכו, למשל) והקפטן ספר: "6 שעות לכיוון מערב במהירות 10".
המהירות חושבה בצורה מדעית למדי: מלח השליך בול עץ (log) למים מחרטום האוניה. מכיוון שהאוניה מהירה יותר (יש לה הנעה מהמפרשים), היא עקפה את בול העץ בהדרגה. המלח ליווה את בול העץ מחרטום האוניה על לירכתיים - ושר לעצמו שיר. ברגע שבול העץ הגיע לקו יכרכתי האוניה, השירה נפסקה ובול העץ נשלף מהמים. ע"פ המקום בו הפסיק השיר נקבעה - מהירות השיט: "אבל את לא מבינה..." - מהירות 7. "...אל תהיי תמימה" - מהירות 6.
הקפטן, מצידו, ניהל מסמך ארוך שנקרא Captain's log שכלל שורה לכל קטע בשיט: <כיוון, מהירות, זמן שיט>.
לפי הרכבת השורות בלוג ניתן היה אפשר לשחזר את מסלול הספינה - ומכאן את מיקומה. כמה מאות ק"מ לפה או לשם...
באופן דומה, בעזרת קובץ לוג של תוכנה, ניתן לשחזר (בצורה גסה) מה התרחש במערכת - ומה בעצם הסיבה לתקלה שאנו רואים (פחות או יותר...)
בכל אופן, log files הם כלי פשוט, אמין - ומאוד שימושי. נרצה להשתמש בהם בלינוקס.
למידע נוסף על ניווט ימי, אני ממליץ להאזין לפרק המצוין של "עושים היסטוריה": פרק 82: האדמירל שהלך לאיבוד- על ניווט ימי ומפות עולם.
פוסט זה הוא חלק מהסדרה: לינוקס / אובונטו

בואו נחפש את קבצי הלוג של מערכת האובונטו. בכדי למצוא קבצים במערכת הקבצים של לינוקס, משתמשים בפקודת find. למשל, כך מחפשים קובץ index.html בתוך התיקיה של המשתמש שלי (~):
אל תתנו לדגומה הקטנה הזו להטעות אתכם: find בלינוקס היא פקודה מבלבלת למדי: יש לה פרמטרים רבים, וחוקים שונים לגביהם.
התחביר שלה בפועל הוא משהו כזה:
הנה דוגמה לכמה חיפושים אפשריים:
תחפש קבצים בסיומת js. הארגומנט iname מחפש ע"פ שם בהתעלמות מ case. כלומר גם סיומת "Js" תמצא. הארגומנט size- מגביל את גודל הקובץ, במקרה שלנו עד 10kB. שימוש ב 10k+ היה מחפש קבצים בגודל 10kB ומעלה.
דוגמה קצת יותר מורכבת:
תחפש את הקבצים של משתמש שאינו (סימן !) המשתמש "baronlior" בתיקיה home/, ובמקום להדפיס את הקבצים למסך - תפעיל עליהם את פקודת הלינוקס touch. הפעולה exec- מקבלת expression כלשהו שנגמר ב ;. באובונטו צריך escaping (כל הפצה מתנהגת מעט שונה) - ולכן ;\ מציין את סוף ה expression. הסוגריים המסולסלים יוחלפו כל פעם בשם הקובץ. לכן המשמעות בפועל היא הפעלת הביטוי הבא על כל קובץ שנמצא:
פקודת touch מעדכנת את ה modification date של הקובץ לזמן הנוכחי. "נוגעת בקובץ, מבלי לשנות את תוכנו באמת".
אם הקובץ לא קיים - היא תיצור אותו. פקודה שאני מוצא כשימושית למדי.
אחד העקרונות של ה shell של לינוקס הוא: "נגעת - נשאת". אין שאלות "Are you sure" גם על פעולות משמעותיות. כדי להמנע מ"תקלה מצערת", ניתן להפעיל את פקודת ה find הנ"ל בצורה הבאה:
ok- הוא כמו exec-, רק שהוא שואל אותנו, קובץ אחר קובץ, אם אנחנו בטוחים.
הנה כמה לינקים עם דוגמאות נוספות לשימוש ב find:
60 דוגמאות מעשיות ל find - חלק א'
60 דוגמאות מעשיות ל find - חלק ב'
15 דוגמאות מעשיות לשימוש ב find (קצר יותר)

טוב... סטינו קצת מהדרך. אנו מחפשים את קבצי ה log של לינוקס. היכן הם יהיו?
אם אתם זוכרים את הפוסט הראשון בסדרה, קבצים בעלי גודל משתנה מאוחסנים בד"כ בתיקיה var/. בואו נחפש:



נשמור את קובץ השגיאות שלנו עכשיו במקום אחר:
מה זה הקובץ הזה? בואו נבדוק:
מה קורה פה?
dev/null/ הוא קובץ מערכת מיוחד, אחד מכמה בודדים במערכת Linux (עד כמה שידוע לי).
dev/null/ הוא סוג של "recycled bin": מה שנשלח אליו - נמחק לעד לפני שתספיקו לומר... "... sudo".
כשאפסים לא מתאימים למשימה, ניתן להשתמש באופן דומה dev/urandom/, שהוא פחות מהיר אך מייצר stream של מספרים פסודו-אקראיים.
קובץ מיוחד אחרון שאזכיר הוא dev/full/, שבכל פעם שננסה לכתוב אליו נקבל שגיאה שהדיסק מלא (שימושי עבור בדיקות).
כן, נכון. התחלנו את המסע הזה בחיפוש אחר הלוגים.
לוגים נמצאים בעקרון בתיקיה var/logs/:

אפשר לראות שלוגים ישנים יותר נדחסים (צבע אדום) בכדי לחסוך מקום. התהליך שעושה זאת נקרא logrotate.
אפשר לראות תיקיות עם עוד logs ע"פ נושאים (apt - התקנות או upstart - תהליך האתחול של אובונטו). כשמותקן שרת Apache, לדוגמה, הוא יאכסן את הלוגים שלו בתיקיית בת בשם /httpd.
כדי לצפות בקובץ שדחוס ב gzip (סיומת gz), יש פשוט להשתמש ב zcat, גרסה של cat שפותחת את הדחיסה on the fly:
אפשר לציין כמה לוגים עקריים:
אפשר למצוא רשימה מקיפה של קבצי הלוג בלינק הכללי הבא ללינוקס או בתיעוד של אובונטו (הקבצים מעט שונים. למשל באובונטו אין קובץ לוג של messages שמאוד נפוץ לשימוש בכל העולם של red hat).
פורמט קבצי הלוג, הוא בברירת המחדל משהו כזה (תלוי בקובץ, ותלוי בהגדרות המערכת):
host, אפרופו, הוא חשוב מכיוון שפעמים רבות מרכזים בעזרת syslog את הלוגים לא על השרת בו התרחשו האירועים.
כדי לנטר בעיות עלייה של המערכת כולה, הכי פשוט להשתמש בפקודה בשם dmesg המרכזת נתונים שונים על טעינת המערכת. כדי להתמצא בשלל המידע, כדאי להשתמש ב grep, כפי שמוסבר במדריך הקצר שבלינק זה.
את הגדרות המערכת, מה הולך לאיזה לוג, ניתן למצוא תחת קבצי הקונפיגורציה של הלוגים בתיקיה etc/rsyslog.d/
הסיומת d. משמשת ב UNIX (ולכן גם בלינוקס) לסמן ספריות, בעיקר כאשר יש קובץ עם שם דומה במערכת.
קובץ ההגדרות הראשי הוא rsyslog.conf (הנמצא במקביל תיקיה rsyslog.d) - המגדיר את המודולים האחראים על הלוגים, הרשאות של קבצי log שיכתבו וכו'.
את ההגדרות היותר שימושיות ניתן למצוא בקובץ ברירת המחדל של הגדרות הלוג etc/rsyslog.d/50-default.conf:

ניתן למשל לראות, שקובץ הלוג של תהליכי הרקע (daemon.log) הוא disabled כברירת מחדל.
עוד טיפ קטן:
כאשר קבצי הלוג גדולים ו / או אתם בוחנים אותם דרך הרשת (למשל ssh) - הטעינה/הצגה שלהם הולכת לקחת זמן. פעמים רבות יעניינו אותנו רק השורות האחרונות, ואז כדאי להשתמש בפקודה tail. למשל:
תציג לנו בתוכנת less רק את 50 השורות האחרונות של קובץ ה syslog. הטריק הוא לקרוא את כל הקובץ ולהציג רק את 50 השורות האחרונות: tail בעצם מבצע seek על הקובץ וקורא רק את הבלוקים האחרונים שלו עד שיש לו את מספר השורות שביקשנו - מה שמיעל דרמטית את זמן הטעינה של הלוג.
עוד דבר נחמד שקיים ב tail הוא הפרמטר f- (קיצור של follow) שיאזין לשינויים בקובץ לוג ויציג אותם ברגע שיתווספו לקובץ. למשל:
מוד זה הוא שימושי למצב שאנו מנטרים מערכת ורוצים לראות את השורות שמתווספות ללוג - בזמן אמת.
עברנו עוד כברת דרך בטיפול בקבצים בלינוקס/אובונטו: פקודת find, קבצים מיוחדים, לוגים, ועוד. לפעמים ה"עוד" הזה הוא החלק החשוב ביותר :)
בתחום הקבצים בלינוקס/אובונטו נותר לנו לדבר בעיקר על הרשאות ו symbolic links...
שיהיה בהצלחה!
משמעות המילה log, כדרך אגב, היא "בול עץ". כיצד בולי-עץ קשורים לקבצי log? הנה סיפור קצר:
בעבר ניווט בים נעשה ע"י סכימת מרחקי שיט שהספינה עברה. הספינה יצאה מנמל (עכו, למשל) והקפטן ספר: "6 שעות לכיוון מערב במהירות 10".
המהירות חושבה בצורה מדעית למדי: מלח השליך בול עץ (log) למים מחרטום האוניה. מכיוון שהאוניה מהירה יותר (יש לה הנעה מהמפרשים), היא עקפה את בול העץ בהדרגה. המלח ליווה את בול העץ מחרטום האוניה על לירכתיים - ושר לעצמו שיר. ברגע שבול העץ הגיע לקו יכרכתי האוניה, השירה נפסקה ובול העץ נשלף מהמים. ע"פ המקום בו הפסיק השיר נקבעה - מהירות השיט: "אבל את לא מבינה..." - מהירות 7. "...אל תהיי תמימה" - מהירות 6.
הקפטן, מצידו, ניהל מסמך ארוך שנקרא Captain's log שכלל שורה לכל קטע בשיט: <כיוון, מהירות, זמן שיט>.
לפי הרכבת השורות בלוג ניתן היה אפשר לשחזר את מסלול הספינה - ומכאן את מיקומה. כמה מאות ק"מ לפה או לשם...
באופן דומה, בעזרת קובץ לוג של תוכנה, ניתן לשחזר (בצורה גסה) מה התרחש במערכת - ומה בעצם הסיבה לתקלה שאנו רואים (פחות או יותר...)
בכל אופן, log files הם כלי פשוט, אמין - ומאוד שימושי. נרצה להשתמש בהם בלינוקס.
למידע נוסף על ניווט ימי, אני ממליץ להאזין לפרק המצוין של "עושים היסטוריה": פרק 82: האדמירל שהלך לאיבוד- על ניווט ימי ומפות עולם.
פוסט זה הוא חלק מהסדרה: לינוקס / אובונטו
חיפוש אחר ... <משהו>
בואו נחפש את קבצי הלוג של מערכת האובונטו. בכדי למצוא קבצים במערכת הקבצים של לינוקס, משתמשים בפקודת find. למשל, כך מחפשים קובץ index.html בתוך התיקיה של המשתמש שלי (~):
find ~ -name index.html
אל תתנו לדגומה הקטנה הזו להטעות אתכם: find בלינוקס היא פקודה מבלבלת למדי: יש לה פרמטרים רבים, וחוקים שונים לגביהם.
התחביר שלה בפועל הוא משהו כזה:
find <symbolic links options> <root path> <search options> <search arguments> <action>
- symbolic links options - נתעלם מחלק זה. כברירת מחדל find לא "נכנסת" ל symbolic links.
- root path - מתחתיו יתבצע החיפוש. אם לא צוין, יהיה . (התיקיה הנוכחית).
- search options - נוגעים לאופן החיפוש: איזה עומק לחפש (depth), האם לחפש ב mounted drives (פרמטר mount-) וכו'.
- search arguments - נוגעים לתכונות הקבצים עצמם: שם, גודל, תאריכים, הרשאות וכו'.
- action - מה לעשות עם הקבצים שהתאימו לחיפוש. ברירת המחדל היא print- (הצגה ל standard output). אפשרויות אחרות כוללות הפעלה פקודה כלשהי בלינוקס (rm, mv וכו').
קצת קשה לזכור את הסדר של סוגי הפרמטרים השונים. אם מתבלבלים בסדר הפרמטרים אזי יופיע warning נוסח "non-option argument", או במקרה הפחות טוב - יקרה משהו שונה ממה שהתכוונתם.
הנה דוגמה לכמה חיפושים אפשריים:
find ~/js_project -iname "*.js" -size -10k
דוגמה קצת יותר מורכבת:
find /home ! -user baronlior -exec touch {} \;
touch <filename>
פקודת touch מעדכנת את ה modification date של הקובץ לזמן הנוכחי. "נוגעת בקובץ, מבלי לשנות את תוכנו באמת".
אם הקובץ לא קיים - היא תיצור אותו. פקודה שאני מוצא כשימושית למדי.
אחד העקרונות של ה shell של לינוקס הוא: "נגעת - נשאת". אין שאלות "Are you sure" גם על פעולות משמעותיות. כדי להמנע מ"תקלה מצערת", ניתן להפעיל את פקודת ה find הנ"ל בצורה הבאה:
find /home ! -user baronlior -ok touch {} \;
ok- הוא כמו exec-, רק שהוא שואל אותנו, קובץ אחר קובץ, אם אנחנו בטוחים.
הנה כמה לינקים עם דוגמאות נוספות לשימוש ב find:
60 דוגמאות מעשיות ל find - חלק א'
60 דוגמאות מעשיות ל find - חלק ב'
15 דוגמאות מעשיות לשימוש ב find (קצר יותר)
חיפוש אחר לוגים
טוב... סטינו קצת מהדרך. אנו מחפשים את קבצי ה log של לינוקס. היכן הם יהיו?
אם אתם זוכרים את הפוסט הראשון בסדרה, קבצים בעלי גודל משתנה מאוחסנים בד"כ בתיקיה var/. בואו נחפש:
find /var -name "*log*" | grep log
כאשר משתמשים ב regex / wildcards - כדאי לעטוף את הערכים במרכאות כדי למנוע בלבול.
אני משתמש גם ב grep, כטריק קטן, בכדי להדגיש את התוצאות.
grep, אם אתם לא זוכרים מהפוסט השני בסדרה, הוא כלי ש"מפלטר" זרם (stream) של טקסט רק לשורות המכילות מילת מפתח - וגם מדגיש את המלים הללו.
grep יכול לעשות יותר מזה. הוספה של פרמטר 2 A- ,למשל, תאמר ל grep להציג 2 שורות נוספות מהטקסט לאחר השורה שבה היה match. הפרמטר הוא A עבור after ויש לו אח מקביל, B, עבור before.
ב grep ניתן להשתמש גם באופן עצמאי בכדי לחפש טקסט בתוך מספר קבצים (ע"פ pattern).
בכל מקרה, הנה התוצאה של החיפוש שלי:
קצת ארוך. בואו נקצר ע"י בקשה של חיפוש אחר תיקיות (type = d) בלבד:
2 תוצאות שמצאנו - נראות בהחלט רלוונטיות.
כפי שניתן לראות יש עוד 4 תיקיות בהן לא הצלחנו לבצע חיפוש - מכיוון שאין לנו הרשאות קריאה בהן. אולי אנחנו מפספסים משהו?
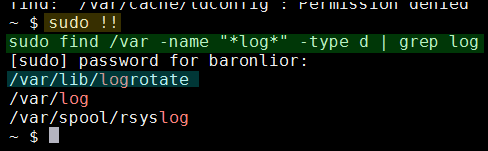
ניתן להשתמש ב sudo.
קצת מעצבן להקליד את השורה הארוכה (נניח) שכבר הרכבנו פעם נוספת, לא?
קצת מעצבן להקליד את השורה הארוכה (נניח) שכבר הרכבנו פעם נוספת, לא?
בעזרת SSH client מתקדם ל ניתן להריץ מחדש עם sudo בקלות יחסית עם העכבר / קופי-פייסט.
יש דרך קלה אפילו יותר, שתעבוד עם ה SSH client הפרימיטיבי ביותר / terminal:
sudo !!
!! הוא משתנה שערכו הוא הפקודה האחרונה שהוקלדה ב shell. לאחר שימוש בפקודה. כאשר אנו משתמשים ב !!, ה history שיזכר הוא כאילו הקלדנו הכל מחדש. מאוד נוח - רק שימו לב לא להקל ראש בשימוש ב sudo עם הטריק הזה.
בעזרת הרשאות sudo, מצאנו עוד תיקיה בשם logrotate. לא תיקיה שמעניינת אותנו כרגע.
בואו נתבונן על תסריט מעט אחר:
נניח שלא ניתן להשתמש ב sudo ויש הרבה תיקיות שאין לנו אליהן הרשאות (מצב הגיוני בשימוש ב find, במיוחד על שרת production). מה עושים? כיצד מפלטרים את כל הודעות השגיאה מהתוכן המשמעותי?
 |
| תזכורת של ה"בעיה" |
אפשר בוודאי לעשות משהו עם grep, אבל אני רוצה לתקוף את הבעיה מכיוון אחר. ננסה:
זהו. אני מרגיש שהתחלנו להיכנס ל hardcore של השימוש ב shell. אני מניח שרוב מפתחי java ו / או C מכירים את 3 הערוצים של מערכת ההפעלה: stdout, stdin ו stderr (הממוספרים 0, 1 ו 2 - בהתאמה).
אלו הם ערוצי ה shell של לינוקס שב C עושים בהם שימוש, וג'אווה אמצה אותם כממשק (תחת המחלקה System):
ישנו ערוץ אחד של קלט (stdin) ושני ערוצי פלט. למרות שאנו רואים על המסך תוצאה של הרצת התוכנה / פקודה כשטף אחד של שורות טקסט, בעצם מערכת ההפעלה מסווגת ומנהלת אותם כ 2 ערוצים שונים:
- stdout הוא קיצור של standard output - תוצאת ההרצה
- stderr הוא קיצור של standard error - שגיאות שהתגלו בהרצה.
בעזרת פעולת I/O redirect (קרי <, <<, אך גם > הנדירה יותר) אנו יכולים לשלוח את התוצאות של פלט התכנית ל stream (קובץ, רשת) שהגדרנו. בעזרת " <n ", כאשר n הוא מספר ערוץ הפלט 1 או 2, אנו יכולים לפצל את הערוצים ולשלוח רק אחד מהם ל stream נבחר.
בפקודה למעלה שלחתי את ערוץ השגיאות לקובץ בשם err.txt, שכפי שניתן לראות בתצוגה שלו מיד לאחר כך - הוא קיבל את כל הודעות השגיאה.
אני מקווה שההסבר מובן.
בפקודה למעלה שלחתי את ערוץ השגיאות לקובץ בשם err.txt, שכפי שניתן לראות בתצוגה שלו מיד לאחר כך - הוא קיבל את כל הודעות השגיאה.
אני מקווה שההסבר מובן.
קבצים מיוחדים
נשמור את קובץ השגיאות שלנו עכשיו במקום אחר:
find /var -name "*log*" -type d 2> /dev/null | grep log
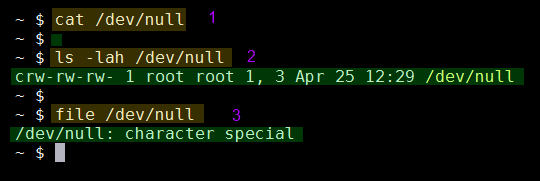
מה זה הקובץ הזה? בואו נבדוק:
- ניסינו להציג את הקובץ - אך שום תוכן לא נראה. היכן השגיאות שלנו?!
- האם קובץ כזה בכלל קיים? בדקנו - וכן, הוא קיים.
- נשתמש ב file לבדוק מאיזה טיפוס הוא. הממ... "סוג מיוחד" (character special)
dev/null/ הוא קובץ מערכת מיוחד, אחד מכמה בודדים במערכת Linux (עד כמה שידוע לי).
dev/null/ הוא סוג של "recycled bin": מה שנשלח אליו - נמחק לעד לפני שתספיקו לומר... "... sudo".
מתי הוא שימושי? כתחליף לקובץ זמני שאנו מתכננים למחוק - אך אנו יכולים לשכוח למחוק (ואז נשאר "זבל"). אני מניח שהוא גם מהיר יותר - כי שום דבר לא נכתב באמת לדיסק.
אם יש לנו פעולה שמייצרת הרבה error, אבל אנו יודעים שזה בסדר ולא רוצים לראות את השגיאות (כמו בדוגמה לעיל) - כתיבה ל dev/null/ במקום err.txt - היא שימושית.
אם יש לנו פעולה שמייצרת הרבה error, אבל אנו יודעים שזה בסדר ולא רוצים לראות את השגיאות (כמו בדוגמה לעיל) - כתיבה ל dev/null/ במקום err.txt - היא שימושית.
קובץ מיוחד נוסף הוא dev/zero שהוא בעצם stream אינסופי של אפסים.
כיצד ניתן להשתמש בכזו חיה מוזרה?
למשל:
cat /dev/zero >> large.txt
ייצר לנו קובץ (מלא אפסים) בגודל כמה MB תוך שניות בודדות. שימושי לצורך בדיקות מקרי-קצה.
הפקודה "cat large.txt" לא תציג שום דבר, כי ערך 0 של ASCII הוא בלתי מוצג (זה לא התו "0", שערך ה ASCII שלו הוא 48). הפקודה:
xxd large.txt | less
דווקא תציג את תוכן הקובץ. xxd - קיצור (משונה) של hex dump. תוכנה זו הופכת מידע בינארי (כלומר: בייצוג הטבעי שלו) לתצוגה בינארית [א]. הצגתי את תוצאת ההמרה בתוך ה viewer הפשוט של לינוקס שנקרא less.
כשאפסים לא מתאימים למשימה, ניתן להשתמש באופן דומה dev/urandom/, שהוא פחות מהיר אך מייצר stream של מספרים פסודו-אקראיים.
קובץ מיוחד אחרון שאזכיר הוא dev/full/, שבכל פעם שננסה לכתוב אליו נקבל שגיאה שהדיסק מלא (שימושי עבור בדיקות).
אבל מה עם הלוגים?!
כן, נכון. התחלנו את המסע הזה בחיפוש אחר הלוגים.
לוגים נמצאים בעקרון בתיקיה var/logs/:
אפשר לראות שלוגים ישנים יותר נדחסים (צבע אדום) בכדי לחסוך מקום. התהליך שעושה זאת נקרא logrotate.
אפשר לראות תיקיות עם עוד logs ע"פ נושאים (apt - התקנות או upstart - תהליך האתחול של אובונטו). כשמותקן שרת Apache, לדוגמה, הוא יאכסן את הלוגים שלו בתיקיית בת בשם /httpd.
כדי לצפות בקובץ שדחוס ב gzip (סיומת gz), יש פשוט להשתמש ב zcat, גרסה של cat שפותחת את הדחיסה on the fly:
zcat syslog.2.gz
אפשר לציין כמה לוגים עקריים:
- syslog - לוג ברירת המחדל להודעות מערכת. syslog הוא לא רק קובץ לוג, אלא גם שם של פרוטוקול להעברת לוגים בין מערכות. למשל: הקצאת שרת אחד עליו יכתבו כל הלוגים של כל שרתי ה production.
- daemon.log - לוג של שירותים שרצים ברקע.
- kernel.log - הודעות קרנל של מערכת ההפעלה.
- auth.log - רשימה של פעולות התחברות למערכת ושימוש בפקודת sudo.
אפשר למצוא רשימה מקיפה של קבצי הלוג בלינק הכללי הבא ללינוקס או בתיעוד של אובונטו (הקבצים מעט שונים. למשל באובונטו אין קובץ לוג של messages שמאוד נפוץ לשימוש בכל העולם של red hat).
פורמט קבצי הלוג, הוא בברירת המחדל משהו כזה (תלוי בקובץ, ותלוי בהגדרות המערכת):
[Timestamp in syslog format] [Host] [Process]: [Message text]
כדי לנטר בעיות עלייה של המערכת כולה, הכי פשוט להשתמש בפקודה בשם dmesg המרכזת נתונים שונים על טעינת המערכת. כדי להתמצא בשלל המידע, כדאי להשתמש ב grep, כפי שמוסבר במדריך הקצר שבלינק זה.
את הגדרות המערכת, מה הולך לאיזה לוג, ניתן למצוא תחת קבצי הקונפיגורציה של הלוגים בתיקיה etc/rsyslog.d/
הסיומת d. משמשת ב UNIX (ולכן גם בלינוקס) לסמן ספריות, בעיקר כאשר יש קובץ עם שם דומה במערכת.
קובץ ההגדרות הראשי הוא rsyslog.conf (הנמצא במקביל תיקיה rsyslog.d) - המגדיר את המודולים האחראים על הלוגים, הרשאות של קבצי log שיכתבו וכו'.
את ההגדרות היותר שימושיות ניתן למצוא בקובץ ברירת המחדל של הגדרות הלוג etc/rsyslog.d/50-default.conf:
ניתן למשל לראות, שקובץ הלוג של תהליכי הרקע (daemon.log) הוא disabled כברירת מחדל.
עוד טיפ קטן:
כאשר קבצי הלוג גדולים ו / או אתם בוחנים אותם דרך הרשת (למשל ssh) - הטעינה/הצגה שלהם הולכת לקחת זמן. פעמים רבות יעניינו אותנו רק השורות האחרונות, ואז כדאי להשתמש בפקודה tail. למשל:
tail -50 syslog | less
תציג לנו בתוכנת less רק את 50 השורות האחרונות של קובץ ה syslog. הטריק הוא לקרוא את כל הקובץ ולהציג רק את 50 השורות האחרונות: tail בעצם מבצע seek על הקובץ וקורא רק את הבלוקים האחרונים שלו עד שיש לו את מספר השורות שביקשנו - מה שמיעל דרמטית את זמן הטעינה של הלוג.
עוד דבר נחמד שקיים ב tail הוא הפרמטר f- (קיצור של follow) שיאזין לשינויים בקובץ לוג ויציג אותם ברגע שיתווספו לקובץ. למשל:
tail -f syslog
סיכום
עברנו עוד כברת דרך בטיפול בקבצים בלינוקס/אובונטו: פקודת find, קבצים מיוחדים, לוגים, ועוד. לפעמים ה"עוד" הזה הוא החלק החשוב ביותר :)
בתחום הקבצים בלינוקס/אובונטו נותר לנו לדבר בעיקר על הרשאות ו symbolic links...
שיהיה בהצלחה!
---
[א] בדומה למצב debug ב DOS - למי שזוכר, אבל אז כל מילה הייתה 16 ביט / 2 בתים.
[א] בדומה למצב debug ב DOS - למי שזוכר, אבל אז כל מילה הייתה 16 ביט / 2 בתים.
תודה על הפוסטים האחרונים בנושא לינוקס.
השבמחקאני מקווה שתמשיך את הסידרה.
שרה.