פוסט זה הוא פוסט המשך לפוסטים:
בפוסט זה נדון באספקט ה"אובייקטים" בשפה.
האם Go היא בכלל שפת Object-Oriented?
בכדי לענות על השאלה, בואו נבחן את שלושת התכונות העיקריות של שפות Object Oriented:
בואו נסתכל על קוד:
אני רוצה שנייה לחזור למילה השמורה type ולהראות שאנו יכולים להגדיר aliases (כמו ב C) או מבנים שלא מבוססים בהכרח על struct. הנה דוגמה למבנה שמבוסס על slice:

כפי שציינו, שפת גו מאמצת במלואה את ההמלצה "prefer composition over inheritance".
אם ניסיתם להימנע מהורשה ולהשתמש רק ב composition בשפות תכנות אחרות (אני ניסיתי בג'אווה) - בוודאי אתם יודעים שזה לא הדבר הכי אלגנטי שקיים:
בשפת גו יצרו תחביר של Composition שחוסך את ה boilerplate code. במבט ראשון - הוא נראה כמו הורשה, אך זו לא הורשה. מבנה B ש composes את מבנה A - לא יכול לגשת או להשפיע על מבנה A שלא דרך המתודות הציבוריות שלו. הבאגים שיכולים להיווצר בגלל תלות שכזו בהורשה - לא יתרחשו בצורת העבודה הזו. מצד שני צורת ה composition לא יכולה להשיג חסכון בקוד-כפול בכמה צורות שהורשה יכולה.
איך עושים זאת?
מבנה בשפת גו יכול להכיל fields שהם embedded (נקראים גם אנונימיים). יכולת זו נקראת Embedded Types.

ממשקים הם הכלי בשפת Go לריבוי-צורות. ממשקים נפוצים בשפה הם io.Reader ו io.Writer שמסתירים מהקוד שלנו את פרטי המימוש הקונקרטי שאנו עובדים איתו (למשל: אמצעי קלט/פלט - דיסק, רשת, מבנה בזיכרון). מי שמגיע משפת ג'אווה, בוודאי מורגל לממשקים דומים. ממשק מפורסם אחר הוא error, המאפשר לנו להתייחס לכל השגיאות, אם אנו רוצים - באותה הצורה.
הבדל חשוב של ממשקים בגו מ"הקלאסיקה של ה OO", היא הרעיון שהם מבטאים:
ב OO מלמדים אותנו לחפש קשר של is-a או לפחות a-substitute-of בין הממשק ומי שמממש אותו, ושפות שונות מספקים כלים שונים לאכוף שאובייקט באמת רשאי למממש ממשק מסוים.
הגישה של גו היא גישה של Duck Typing שאומרת כך: "אם זה נראה כמו ברווז, ומשמיע קול של ברווז - אז זה ברווז!"
כלומר: אין צורך להגדיר שמבנה מסוים מממש ממשק (למשל: כמו המלה השמורה implements בג'אווה).
אם למבנה יש את התכונות הנדרשות (מתודות עם אותה החתימה שהוגדרה בממשק) - אז הוא נחשב אוטומטית לטיפוס הזה.
מצד אחד - זה חוסך את הצורך להגדיר "כן, אני רוצה להיות חלק מהממשק". העניין הוא לא כתיבת עוד מילה או שתיים בקוד, אלא אמור למנוע פתיחת קוד קיים (שאולי לא בשליטתנו, למשל: ספרייה שאנו משתמשים בה).
מצד שני - זה מקום לטעויות. יכול להיות שיש חתימה של מתודה עם שם מסוים, ולי כמכנת, נדמה שאכן המבנה יתמוך בהתנהגות שאני מצפה לה. נדמה, אולם אם הייתי מתייעץ אם מי שכתב את הקוד הייתי מבין שמסיבה כלשהי - לא כך הדבר.
גישת ה Duck Typing אם כן, מציגה tradeoff עם יתרונות וחסרונות - אולם זו גישה מקובלת ושנחשבת בהחלט סבירה. בשפת פייטון גישה זו הוכיחה את עצמה כישימה, גם בפרספקטיבה של זמן.
בואו נראה כיצד משתמשים בממשקים בקוד:

עד כאן הכל נראה פשוט. אם אתם מגיעים מג'אווה / #C, אתם בוודאי אומרים לעצמם: "זהו: את העניין של ממשקים ב Go - כבר הבנתי!".
קחו עוד מעט אוויר. נותרו עוד מספר נקודות שעליכם לדעת על interfaces בגו בכדי לא-להסתבך איתם. התבוננו על דוגמת הקוד הבאה:


כאשר שולחים מצביע ל value receiver הקופיילר יכול לתקן זאת בקלות - ולשכתב את הקוד כך שישלח את הערך עליו מצביע הפויינטר. מי שכתב את המתודה מצפה לקבל עותק - וזה מה שהוא קיבל.
אם הקופיילר יתערב בשליחה של מבנה קונקרטי ל pointer receiver ויהפוך אותו למצביע, הוא מטעה את אחד הצדדים: או שהמתודה תניח שיש לה פויינטר ותבצע שינויים שיתעלמו מהם (כי מה שהועבר הוא עותק), או שמי ששולח ערך מניח שלא יכולים לשנות לו את הערך (הוא לא שלח פויינטר) - אך פתאום הערך יישתנה.
בכל אחד המקרים הנ"ל יכול להיווצר באג קשה ומתסכל למציאה. היוצרים של Go העדיפו לייצר שגיאת קומפילציה ולתת למתכנת להחליט איזו התנהגות הוא מעדיף.
הטיפוס {}interface הוא הממשק שאינו מכיל שום מתודות. ע"פ Duck Typing - מי מספק ("מממש") אותו? כולם!
זה אומר שזהו טיפוס-על שמייצג את כל הטיפוסים בשפה. ניתן להשוות אותו לביטוי *void (הידוע כ generic data pointer) בשפת C, אם כי {}interface הוא בטוח יותר לשימוש.
אילו טיפוסים ניתן להעביר בעזרת {}interface? האם אפשר להעביר int?
בואו נראה את דוגמת הקוד הבאה:

אפשר!
interface בשפת גו הוא בעצם סוג של פויינטר כפול. ניתן לתאר אותו כמבנה (הדמיוני) הבא:

מצביע ראשון: interface-table (מסוג itab) - מבנה המכיל metadata של הטיפוס (שם הטיפוס, הגודל שלו בזיכרון) ואת רשימת המתודות המשויכות לטיפוס הזה.
מצביע שני: data - הכתובת בזיכרון מה מאוחסנים הנתונים. "200" עבור int או רצף התווים של struct מסוים.
הנה pitfall בשפה שניתן להיתקל בו:

אז מה בעצם השימושים הפרקטיים של {}interface? כנראה שלא לעשות המרה מטיפוס ל {}interface, ואז מ{}interface לטיפוס בחזרה...
מייד נראה שימוש מעט אחר בממשקים, המשמש עבור נקודות בקוד בהן אנו כן רוצים לדעת את המימוש הקונקרטי שמאחורי הממשק - אך לטפל ביחד בכמה טיפוסים שונים.
הנה פונקציה שממירה משתנה כלשהו (לא טיפלתי בכל המקרים) - לערך שניתן לשלוח לשאילתת SQL.

הנה דוגמת הקוד כאשר אנו משתמשים ב type switch:

ממשקים הוא אחד מהיסודות החשובים בשפת Go. אם אתם מגיעים משפת C - זהו אלמנט חדש. אם אתם מגיעים מ ++C, ג'אווה או פייטון - הוא כנראה מוכר יותר, אך עדיין מעט שונה.
מבנים והרכבת טיפוסים - גם הם חשובים, ומשמשים ככלי מרכזי לפתרון בעיות ב Go.
לאחר פוסט זה אמור להיות לכם מושג דיי טוב על תיאור "אובייקטים" וממשקים בשפת גו - והשימוש בהם.
שיהיה בהצלחה!
----
לינקים רלוונטיים
Drill Down על ממשקים בגו:
פוסט של Jordan Relly (כיסינו את הרוב בפוסט) ופוסט של Russ Cox (ממש כיצד מומשו בשפה).
בפוסט זה נדון באספקט ה"אובייקטים" בשפה.
האם Go היא בכלל שפת Object-Oriented?
בכדי לענות על השאלה, בואו נבחן את שלושת התכונות העיקריות של שפות Object Oriented:
- הכמסה (encapsulation): מוגבלת. יש הכמסה ברמת החבילה, אך לא ברזולוציה קטנה יותר.
- ריבוי צורות (polymorphism): יש. בעזרת ממשקים - שנראה בפוסט זה.
- הורשה (inheritance): אין. משום סוג. הדרך ללכת בה היא composition.
50% התאמה לעקרונות הבסיס => Go איננה שפת Object Oriented.
בכל זאת, מי שרגיל לתכנות OO, וארגון הקוד ע"פ אובייקטים הכוללים נתונים והתנהגות יחדיו - יגלה שעקרונות ארגון הקוד גם לא מאוד שונים.
אם אומרים על שפת JavaScript שהיא שפה "מבוססת אובייקטים" (היא לא מונחית-אובייקטים) כי יש בה אובייקטים, אך לא מחלקות - שפת Go היא רחוקה יותר מזה. ב Go ישנם "אובייקטים פתוחים", שרואים להם את השלד והאיברים הפנימיים: Structs ומתודות מקושרות.
הייתי מתאר את Go כשפה הנעזרת באובייקטים Object Aided Programming. היא מאמצת רק חלק מהרעיונות והחשיבה של תכנות מונחה-עצמים. האובייקטים הם כבר לא במרכז, אלא הפונקציות וה Structs - כשני אלמנטים נפרדים.
 |
| מקור: spf13 |
אובייקטים... מבנים ב Go
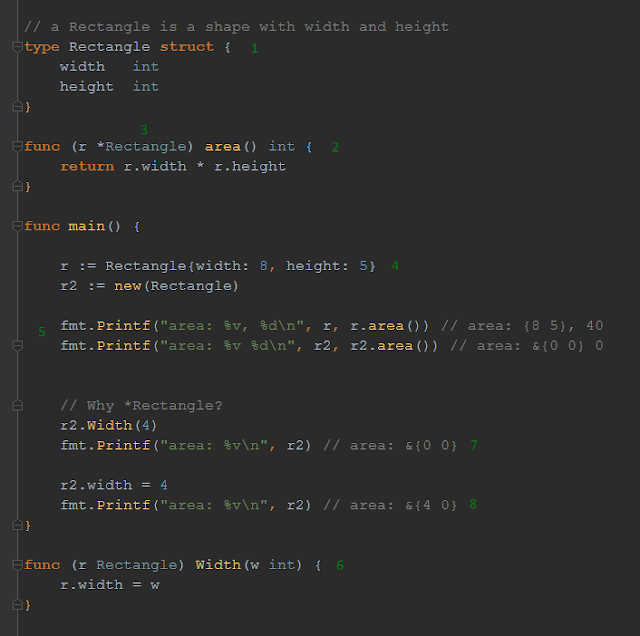
בואו נסתכל על קוד:

- אנו מגדירים טיפוס חדש בשם Rectangle שהוא בעצם struct עם 2 שדות: width ו height.
- שימו לב שאנו מתעדים את ה Struct ע"פ קונבנציית התיעוד של גו: ...a Rectangle is
- בשלב זה אנו מגדירים מתודה, שמקבלת Rectangle ומחזירה int שהוא שטח המרובע.
- בהגדרה, מתודה היא פונקציה עם receiver (לפעמים נקרא גם handler).
- מתודה היא כזו שמשנה State (את זה של ה Struct = מבנה), פונקציה היא stateless.
- מתודה ניתן להפעיל רק דרך רפרנס למבנה (כמעט אמרתי... אובייקט) כלומר (...)myStuct.myMethod, בניגוד לפונקציה שמפעילים ללא תלות, כלומר (...)myFunction.
- הסוגריים המשונים הללו לפני שם המתודה הם ה receiver.
- גו מחברת את הפרמטר של ה receiver (תמיד יש אחד) לשאר הפרמטרים של הפונקציה - כך שהוא תמיד יהיה ראשון. זה קורה מאחורי הקלעים.
- כלומר: החתימה של המתודה area היא בעצם, מתחת למכסה המנוע:
area(r * Rectangle) int. - הרבה יותר נוח לקרוא קונטקסטואלית את הביטוי ()rect.area, מאשר את (area(rect - ולכן ה syntactic sugar הזה.
- הקונבנציה המקובלת היא לפרמטר של ה receiver באות הראשונה של הטיפוס (אות קטנה), או אולי קיצור של כמה אותיות קטנות. למשל: s או sb עבור stringBuffer.
אם אתם מנסים לקרוא ל reference לטיפוס בשם גנרי - זה סימן שלא השתחררתם עדיין משפת התכנות הקודמת שלכם: - this (ג'אווה או #C?)
- that (ג'אווהסקריפט, אולי?)
- self (רובי?)
- __self__ (פייטון! - תפסנו אתכם)
- אם בקוד המתודה אתם לא משתמשים בפרמטר של ה receiver (בדוגמה שלנו: r) - זהו smell שאתם זקוקים כאן ל function ולא למתודה.
- אם בקוד המתודה אתם לא משתמשים ב fields פנימיים של ה struct (אלא רק מתודות אחרות) - ייתכן שעדיף להשתמש בפונקציה רגילה שמקבלת את ה struct כפרמטר.
- הנה שימוש בקוד. אנו יוצרים שני מבנים: r ו r2.
שימו לב ש r2 הוא מצביע ל Rectangle - כי השתמשנו במילה השמורה new. - אנו מדפיסים את תוכן ה Structs. הסימן & בהערה מציין שמדובר במצביע - אך שימו לב שאופן השימוש הוא זהה. בעזרת ה dot notation לא היינו צריכים לכתוב ()r2.area* מתוך ההבנה שזה פויינטר, וגם לא בקיצור כמו ()r2->area של ++C. הקומפיילר מזהה שהשתמשנו ב dot notation על מצביע, ומוסיף את ה * עבורנו, מאחורי הקלעים.
- עכשיו בואו נענה על השאלה: מדוע ה receiver (סעיף #3) קיבל את Rectangle כפונייטר (קרי Rectangle*)? האם חובה להשתמש בפויינטר?
- לצורך התרגיל נגדיר את המתודה Width (אות גדולה = שלפן) שמקבלת את Rectangle לא כפויינטר.
- כאשר אנו משתמשים במתודה - אנו רואים שהערך לא השתנה: הצבנו 4, אך הערך נשאר 0.
מדוע זה קרה?! בגלל שהעברנו למתודה העתק של r2 עליו התבצע השינוי. r2 עצמו לא השתנה. - הנה הבדיקה שאכן כך הדבר: כאשר אנו משנים את r2.width ישירות - הערך משתקף בהדפסה.
מפה עולה השאלה: מדוע בכלל לאפשר ליצור value receiver? מדוע הקומפיילר לא מגן עלינו ומחייב ש receiver יהיה רק pointer receiver? האם מתודה לא נועדה לשנות את ה state של המבנה המדובר?
התשובה היא לא-בהכרח.
- value receiver הוא שימושי כאשר מעבירים פונקציה, map, או channel (שהם כבר בעצמם מצביעים). ההעתקה של הערך יכולה להיות יותר יעילה מגישה לפויינטר שמצביע לאזור שאינו ב cache של המעבד.
slice הוא גם מצביע, אלא אם המתודה עשויה להקצות ל slice מערך חדש - ואז יש להשתמש בפויינטר. - value receiver הוא שימושי כאשר מדובר במתודה שהיא immutable, כלומר - העברה כ value (העתקה) מבטיחה שלא נוכל לשנות את ה state של ה struct.
בקיצור: אם אתם לא בטוחים - השתמשו ב pointer receiver. אם הזמן אולי תגלו את הצרכים ב value receiver גם כן.
אני רוצה שנייה לחזור למילה השמורה type ולהראות שאנו יכולים להגדיר aliases (כמו ב C) או מבנים שלא מבוססים בהכרח על struct. הנה דוגמה למבנה שמבוסס על slice:
הרכבת טיפוסים (Composition)
כפי שציינו, שפת גו מאמצת במלואה את ההמלצה "prefer composition over inheritance".
אם ניסיתם להימנע מהורשה ולהשתמש רק ב composition בשפות תכנות אחרות (אני ניסיתי בג'אווה) - בוודאי אתם יודעים שזה לא הדבר הכי אלגנטי שקיים:
- נניח שאנו רוצים לדמות מחלקה B שיורשת ממחלקה A.
- במחלקה B נוסיף שדה a שיכיל מצביע לאובייקט מסוג A.
- למחלקה B נוסיף את כל המתודות של מחלקה A, ובכל מתודה x נקרא בעצם ל a.x עם הפרמטרים שהעבירו לנו. זהו קוד boilerplate שמרגיש דיי מיותר - במיוחד ככל שלמחלקה A יש יותר מתודות.
בשפת גו יצרו תחביר של Composition שחוסך את ה boilerplate code. במבט ראשון - הוא נראה כמו הורשה, אך זו לא הורשה. מבנה B ש composes את מבנה A - לא יכול לגשת או להשפיע על מבנה A שלא דרך המתודות הציבוריות שלו. הבאגים שיכולים להיווצר בגלל תלות שכזו בהורשה - לא יתרחשו בצורת העבודה הזו. מצד שני צורת ה composition לא יכולה להשיג חסכון בקוד-כפול בכמה צורות שהורשה יכולה.
איך עושים זאת?
מבנה בשפת גו יכול להכיל fields שהם embedded (נקראים גם אנונימיים). יכולת זו נקראת Embedded Types.
- אנו מגדירים את המבנה Person שמכיל שם, ומתודה sayHello.
- אנו מגדירים את המבנה Student שמכיל Person ושם מחלקה, ומתודה sayHello.
- שימו לב שבהגדרת ה Person לא ציינו שם של המשתנה (רק טיפוס). זהו embedded type שגורם להרחבה (extend).
- בפעולה זו אנו גורמים לכל ה fields והמתודות של Person להופיע ברשימת ה fields והמתודות של Student - דומה מאוד ל extend של מודול בשפת רובי. ה fields והמתודות עדיין נשמרים במבנה Person ומתנהגים כפי שהיו מתנהגים לו Person היה field מהמניין. נראה את ההתנהגות המדויקת מייד.
- אם למבנה החיצוני (Student) יש מתודות / fields עם שם זהה למבנה הפנימי (Person) - הם תמיד יקבלו קדימות, ובפועל "יסתירו" את המתודות / fields של המבנה הפנימי.
- ניתן עדיין לגשת למתודות של המבנה הפנימי בצורה מפורשת, קרי: student.Person.Name.
- בשונה מהורשה, אם מתודה של Person תקרא ל field או מתודה שקיימים גם ב Student - היא תמיד תגיע ל field / מתודה ב Person, ואף-פעם לא ל Student. ניתן לומר ש invocation "הועבר" למבנה הפנימי (Person) ופועל עליו.
חלק מהכוח של הורשה, בוא בכך שמחלקה היורשת מחליפה התנהגויות שמשפיעות גם על המתודות של מחלקת האב. התנהגות זו עלולה לגרום לבאגים מתסכלים, אם כי היא גם מאפשרת דפוסי-עבודה שיכולים לחסוך לא-מעט קוד. - הנה אנו יוצרים מופע של המבנה Student, ובתוכו את המבנה של Person. שם ה field שמחזיק את המבנה הפנימי הוא כשם הטיפוס של אותו מבנה. הבחור שלנו, ג'ון, נרשם באקדמיה בצורה לא מוסברת בשם "פופה".
- תזכורת: ברשימות של איברים בגו יש להוסיף פסיק גם לאחר האיבר האחרון. זה מקבל על הוספת / הסרת איברים ללא שבירת הקומפילציה.
- הנה אנו מדפיסים את student, ורואים כיצד הוא מיוצג בזיכרון - כמבנה מקונן.
- כאשר אנו קוראים ל sayHello אנו מגיעים למתודה של המבנה החיצוני בהכרח (יש לה קדימות). הערך של שדה Name הוא זה של אותו המבנה.
- כאשר אנו קוראים ל sayHello של Person בצורה מפורשת - אנו מגיעים למתודה של המבנה Person. הערך של שדה Name הוא זה של אותו המבנה, קרי Person.
ממשקים (Interfaces)
ממשקים הם הכלי בשפת Go לריבוי-צורות. ממשקים נפוצים בשפה הם io.Reader ו io.Writer שמסתירים מהקוד שלנו את פרטי המימוש הקונקרטי שאנו עובדים איתו (למשל: אמצעי קלט/פלט - דיסק, רשת, מבנה בזיכרון). מי שמגיע משפת ג'אווה, בוודאי מורגל לממשקים דומים. ממשק מפורסם אחר הוא error, המאפשר לנו להתייחס לכל השגיאות, אם אנו רוצים - באותה הצורה.
הבדל חשוב של ממשקים בגו מ"הקלאסיקה של ה OO", היא הרעיון שהם מבטאים:
ב OO מלמדים אותנו לחפש קשר של is-a או לפחות a-substitute-of בין הממשק ומי שמממש אותו, ושפות שונות מספקים כלים שונים לאכוף שאובייקט באמת רשאי למממש ממשק מסוים.
הגישה של גו היא גישה של Duck Typing שאומרת כך: "אם זה נראה כמו ברווז, ומשמיע קול של ברווז - אז זה ברווז!"
 |
| Duck Typing. לצורך העניין - זה יכול להיחשב כברווז. |
כלומר: אין צורך להגדיר שמבנה מסוים מממש ממשק (למשל: כמו המלה השמורה implements בג'אווה).
אם למבנה יש את התכונות הנדרשות (מתודות עם אותה החתימה שהוגדרה בממשק) - אז הוא נחשב אוטומטית לטיפוס הזה.
מצד אחד - זה חוסך את הצורך להגדיר "כן, אני רוצה להיות חלק מהממשק". העניין הוא לא כתיבת עוד מילה או שתיים בקוד, אלא אמור למנוע פתיחת קוד קיים (שאולי לא בשליטתנו, למשל: ספרייה שאנו משתמשים בה).
מצד שני - זה מקום לטעויות. יכול להיות שיש חתימה של מתודה עם שם מסוים, ולי כמכנת, נדמה שאכן המבנה יתמוך בהתנהגות שאני מצפה לה. נדמה, אולם אם הייתי מתייעץ אם מי שכתב את הקוד הייתי מבין שמסיבה כלשהי - לא כך הדבר.
גישת ה Duck Typing אם כן, מציגה tradeoff עם יתרונות וחסרונות - אולם זו גישה מקובלת ושנחשבת בהחלט סבירה. בשפת פייטון גישה זו הוכיחה את עצמה כישימה, גם בפרספקטיבה של זמן.
בואו נראה כיצד משתמשים בממשקים בקוד:
- אנו משתמשים במילה השמורה type בכדי להגדיר טיפוס מסוג ממשק בשם statusReporter, המכיל 2 מתודות.
- אנו עכשיו מגדירים פונקציה שמקבלת statusReporter כפרמטר, ומבצעת עליה פעולה כלשהי - בהתבסס על מתודות של הטיפוס (Status ו LastErrors).
- הנה הגדרנו איזה מבנה (=~אובייקט) שיש לו, במקרה או לא במקרה - מתודות עם חתימה זהה.
- אנחנו יכולים לשלוח כל טיפוס שעונה לתנאי הממשק - כפרמטר לפונקציה printStatus שהגדרנו.
מבט מתקדם על Interfaces בשפת Go
עד כאן הכל נראה פשוט. אם אתם מגיעים מג'אווה / #C, אתם בוודאי אומרים לעצמם: "זהו: את העניין של ממשקים ב Go - כבר הבנתי!".
קחו עוד מעט אוויר. נותרו עוד מספר נקודות שעליכם לדעת על interfaces בגו בכדי לא-להסתבך איתם. התבוננו על דוגמת הקוד הבאה:

- אנו מגדירים interface בשם HelloSayer.
- אנו יוצרים מבנה בשם מר זאב, העונה לממשק (עם value receiver).
- אנו יוצרים מבנה בשם גברת נץ, העונה לממשק (עם pointer receiver).
- אנו מאחסנים 2 זאבים (מצביע, ומופע קונקרטי) ו2 נצים (גם מצביע ומופע קונקרטי - שתי האפשרויות הרלוונטיות) - בתוך slice מטיפוס HelloSayer. עצם ההשמה גורמת ל upcasting של ה references ל ממשק.
מה זה משנה אם יש לנו value receiver או pointer receiver?
האם בכלל לא צריך להתאים בין הערך ששולחים ל receiver?!
התשובה היא שמקרים A-C יעבדו בצורה תקינה, אך מקרה D יגרום לשגיאת קומפילציה "SayHello has pointer receiver" - שגיאה שבוודאי תתקלו בה בעבודה שלכם בגו, שגיאה שהיא קשה להבנה ללא הרקע המתאים.
מדוע דווקא מקרה D הוא זה שנכשל?
האם נחליף את הביטוי D ב "{}Hawke&", כלומר נשלח מצביע למבנה - הדברים ייסתדרו? (כן)
מדוע זה עובד כך?
יש יותר מדרך אחת להסביר זאת, אני אבחר בהסבר של הברירות שהיו למתכנני שפת Go - נראה לי שזה האופן הפשוט ביותר להסביר זאת.
בגדול אנו רואים שניתן לשלוח למתודה עם value receiver גם מופע (A) וגם פויינטר (C), אך למתודה עם pointer receiver ניתן לשלוח רק פויינטר (B).
שפת גו מנסה:
- לחסוך למתכנת "עבודה שחורה" - כל עוד הדבר לא פוגע בביצועי ריצה או ביצועי ההידור בצורה מיוחדת.
- להיות עקבית וצפויה, ולחסוך מהמתכנת "באגים חמקמקים".
כאשר שולחים מצביע ל value receiver הקופיילר יכול לתקן זאת בקלות - ולשכתב את הקוד כך שישלח את הערך עליו מצביע הפויינטר. מי שכתב את המתודה מצפה לקבל עותק - וזה מה שהוא קיבל.
אם הקופיילר יתערב בשליחה של מבנה קונקרטי ל pointer receiver ויהפוך אותו למצביע, הוא מטעה את אחד הצדדים: או שהמתודה תניח שיש לה פויינטר ותבצע שינויים שיתעלמו מהם (כי מה שהועבר הוא עותק), או שמי ששולח ערך מניח שלא יכולים לשנות לו את הערך (הוא לא שלח פויינטר) - אך פתאום הערך יישתנה.
בכל אחד המקרים הנ"ל יכול להיווצר באג קשה ומתסכל למציאה. היוצרים של Go העדיפו לייצר שגיאת קומפילציה ולתת למתכנת להחליט איזו התנהגות הוא מעדיף.
{}interface
הטיפוס {}interface הוא הממשק שאינו מכיל שום מתודות. ע"פ Duck Typing - מי מספק ("מממש") אותו? כולם!
זה אומר שזהו טיפוס-על שמייצג את כל הטיפוסים בשפה. ניתן להשוות אותו לביטוי *void (הידוע כ generic data pointer) בשפת C, אם כי {}interface הוא בטוח יותר לשימוש.
אילו טיפוסים ניתן להעביר בעזרת {}interface? האם אפשר להעביר int?
בואו נראה את דוגמת הקוד הבאה:
אפשר!
- האם {}interface מאפשר dynamic typing בשפת Go?
- לא. יש לו טיפוס סטאטי ומוגדר היטב. אפרט מייד.
- מהו, אם כן, הטיפוס של i בדוגמה לעיל?
- הטיפוס הוא {}interface. גו מבצעת type conversion על 1 ל {}interface, ואז חזרה בהדפסה.
- האם אפשר להחיל את הכלל הזה גם על מערך / רשימה? כלומר: להעביר int[] כ {}interface[]?
- לא. ניתן להעביר int[] כ {}interface (כי הוא טיפוס בשפה - slice) - אך הוא שונה מהותית "מערך של טיפוסים". אם רוצים לבצע את ההעברה יש לעשות עבודת העתקה ידנית.
interface בשפת גו הוא בעצם סוג של פויינטר כפול. ניתן לתאר אותו כמבנה (הדמיוני) הבא:
מצביע ראשון: interface-table (מסוג itab) - מבנה המכיל metadata של הטיפוס (שם הטיפוס, הגודל שלו בזיכרון) ואת רשימת המתודות המשויכות לטיפוס הזה.
מצביע שני: data - הכתובת בזיכרון מה מאוחסנים הנתונים. "200" עבור int או רצף התווים של struct מסוים.
הנה pitfall בשפה שניתן להיתקל בו:
- נגדיר קבוע שמגדיר האם אנו אוספים נתונים ל BI או לא.
- נגדיר את buf מטיפוס Buffer. הטיפוס Buffer מספק את הממשק io.Writer.
- אם אנו במצב של איסוף נתונים - ניצור את ה buf, אחרת - אין טעם.
- פונקציית Perform מבצעת איזו לוגיקה עסקית, וכותבת נתונים שנאספו ל io.Writer.
יש הגנה במידה וה io.Writer שנשלח לה הוא nil.
מה תוצאת הריצה?
- אם collectData == true - התוכנה תתנהג כצפוי.
- אם collectData == false, אנו נקבל שגיאת panic שאומר כך: invalid memory address or nil pointer dereference. כלומר: ניסינו להשתמש במצביע שהוא nil.
איך זה קרה?
מה יכולנו לעשות טוב יותר??
התהליך שגרם לשגיאה הוא כזה:
מה יכולנו לעשות טוב יותר??
התהליך שגרם לשגיאה הוא כזה:
- במידה ו collectData הוא false, אין השמה ל buf - והוא נשאר nil.
- כפי שאמרנו ממשק הוא לא מצביע. כאשר אנו קוראים ל perform סביבת הריצה מבצעת עבורנו type conversion מ Buffer ל io.Writer.
out, שהוא מטיפוס ממשק io.Writer, מכיל עכשיו שני מצביעים: iTable שמצביע על Buffer (טיפוס + רשימת מתודות), ו data שהוא nil. - בשלב #4 בקוד לעיל אנו בודקים אם out הוא nil, אבל הוא לא. הוא מבנה תקין מסוג ממשק שמכיל מצביע אחד לטיפוס, ומצביע שני שהוא nil.
באסה... מה עושים? איך לא נופלים בפח הזה?
ראשית - אתם צודקים. זו התנהגות "מכשילה" של השפה. לזכותה של Go אציין שיש לה הרבה פחות התנהגויות מכשילות מרוב השפות שאני מכיר. בעצם: ככל הנראה זו השפה הכי פחות מכשילה שאני מכיר.
אז מה עושים?
- לבצע בשלב #4 (וכל מקום אחר בקוד שמקבל רפרנס) בדיקה עמוקה יותר של nil. ג'אווהסקריפט מישהו? שיש בה גם null וגם undefined? - ממש לא! זו אופציה גרועה למדי.
- ניתן ליצור את Buffer בכל מקרה, ולבצע עבודה שלא נדרשת בכדי להימנע מטעויות. זו גם אופציה גרועה.
- הדרך הנכונה לתקן זאת היא להגדיר מראש (בשלב #2) את buf כממשק (קרי io.Writer ולא כ Buffer).
buf יישאר nil עד שיושם לו ערך (שלב #3), ואז שני המצביעים של הממשק יתמלאו במקביל בערכים.
שימושים של {}interface
אז מה בעצם השימושים הפרקטיים של {}interface? כנראה שלא לעשות המרה מטיפוס ל {}interface, ואז מ{}interface לטיפוס בחזרה...
מייד נראה שימוש מעט אחר בממשקים, המשמש עבור נקודות בקוד בהן אנו כן רוצים לדעת את המימוש הקונקרטי שמאחורי הממשק - אך לטפל ביחד בכמה טיפוסים שונים.
הנה פונקציה שממירה משתנה כלשהו (לא טיפלתי בכל המקרים) - לערך שניתן לשלוח לשאילתת SQL.
- למשל: לא ניתן לשלוח nil ולכן הפכתי אותו למה שבסיס הנתונים מכיר - "NULL".
- הביטוי (x.(int בוודאי נראה מעט מוזר. זהו ביטוי מיוחד בשפה הנקרא type assertion שבודק בו-זמנית שני דברים: ש x הוא לא nil, וגם ש x מתאים לטיפוס (או הממשק) שצוין - במקרה שלנו: int.
הביטוי מחזיר שני ערכים כתשובה: - הערך השני ("ok") הוא bool שמציין אם ה assertion הצליח - כלומר: x הוא int שאינו nil.
- הערך הראשון הוא הערך של x על פי הטיפוס שהגדרנו (קרי int). הוא יקבל ערך אפס - אם ה assertion אינו נכון.
- Sprintf או כמו Printf, אך במקום לשלוח את הקלט ל default output הוא מחזיר אותו כמחרוזת.
- עתה אנו עושים אותו תרגיל על bool, אך במקרה זה אנו רוצים לשמור את הערך.
מדוע אנו משתמשים ב val? מדוע לא לשאול if x? - הקומפיילר לא יאפשר לנו ויכשיל אותנו בבדיקת טיפוסים. הוא יאמר שלא ניתן להגדיר תנאי if על {}interface. המשתנה val מוכר לקומפיילר כ bool. - ב Go אין ternary if (כלומר: : ?). חבל.
- panic הוא סוג של Exception פנימי של סביבת הריצה של גו. שההנחיה היא לא להשתמש בו - אולי רק במקרים קיצוניים. האם יש במקרה זה צידוק להשתמש ב panic?
מצד אחד: כאשר משתמשים ב type assertion מבלי לשמור את ערך ההחזרה השני ("ok") - גו תזרוק panic.
מצד שני: זה לא המקרה אצלנו, ויש לנו בחירה מה לעשות.
זהו דיון ראוי שאינני רוצה לנהל כרגע. בעיקר רציתי לציין את התנהגות ה panic של ה type assertion.
משהו היה מוזר לכם בדוגמה לעיל? כמובן - הקונבנציה בגו היא להימנע מ if else if!
בשפה יש אופרטור דומה מאוד ל type assertion הנקרא type switch.
הנה דוגמת הקוד כאשר אנו משתמשים ב type switch:
- הביטוי הוא דיי דומה, כאשר בתוך הסוגריים אנו מציינים את המילה השמורה type. ביטוי זה יכול לעבוד רק כחלק מ ל switch statement.
- זה idiom מעט מבלבל: יכולנו לכתוב (val := x.(type ואז להשתמש בהמשך הפונקציה ב val - מה שהיה מפחית כנראה את הבלבול.
בשפת Go ביטוי switch מגדיר scope משלו, scope שמתחיל שמתחיל מייד לאחר המילה switch. לכן ניתן להגדיר (x := x.(type, כאשר ה x הימני הוא זה שהוגדר ב scope הפונקציה, מטיפוס {}interface, וה x השמאלי הוא ב scope של ה switch בלבד - ויוכר כטיפוס שהוא בפועל. זה ה idiom. - המשך הפונקציה כנראה ברורה - וגם פשוטה יותר מהגרסה הקודמת.
סיכום קצר
ממשקים הוא אחד מהיסודות החשובים בשפת Go. אם אתם מגיעים משפת C - זהו אלמנט חדש. אם אתם מגיעים מ ++C, ג'אווה או פייטון - הוא כנראה מוכר יותר, אך עדיין מעט שונה.
מבנים והרכבת טיפוסים - גם הם חשובים, ומשמשים ככלי מרכזי לפתרון בעיות ב Go.
לאחר פוסט זה אמור להיות לכם מושג דיי טוב על תיאור "אובייקטים" וממשקים בשפת גו - והשימוש בהם.
שיהיה בהצלחה!
----
לינקים רלוונטיים
Drill Down על ממשקים בגו:
פוסט של Jordan Relly (כיסינו את הרוב בפוסט) ופוסט של Russ Cox (ממש כיצד מומשו בשפה).












